
Build Your Software Modernization Roadmap
Most software modernization roadmap advice starts in the wrong place. It starts with architecture, tooling, and migration patterns. That’s backwards.
A roadmap is not a vision document. It’s a capital allocation and risk control document. If you treat it like an engineering wishlist, you’ll fund work that looks modern on slides and fails in production. That failure pattern isn’t edge-case behavior. It’s common.
CTOs are under pressure to move fast because software modernization spending is rising aggressively. The U.S. Department of Defense’s FY25-26 Software Modernization Implementation Plan says modernization-related spending has grown at about 50% annually (DoD software modernization implementation plan). Pressure like that pushes bad decisions into portfolio plans. Teams start programs because the market says “modernize,” not because the economics and operating model justify the move.
If you need a business-side framing for that pressure, CloudOrbis has a useful piece on how to transform your business IT without pretending every legacy platform deserves a rebuild.
The Hard Truth About Modernization Roadmaps
The standard roadmap template is optimistic fiction. It assumes clear requirements, rational sequencing, stable dependencies, and organizational alignment that rarely exists outside a conference keynote.
That’s why the software modernization roadmap has to start with a harsher question than “how do we modernize?” Start with “what would make this a bad investment?” If your roadmap doesn’t answer that, it’s incomplete.
Most roadmaps hide risk instead of exposing it
A serious roadmap does three things.
- Defines the business reason: It ties the application to revenue protection, security posture, operational resilience, or strategic delivery capacity.
- Surfaces failure conditions early: It identifies where data conversion, dependency breakage, compliance drift, or skills gaps can sink the effort.
- Creates exit options: It gives leadership a rational basis to pause, narrow scope, or retire a system instead of blindly funding the original plan.
A clean migration diagram is not evidence. It’s often a sign the team hasn’t found the ugly parts yet.
The practical mistake is treating legacy systems as technical debt only. Many are also process debt, documentation debt, and staffing debt. Moving them to Kubernetes or a hyperscaler doesn’t remove that burden. It often hardens it into a more expensive operating model.
Think like an investor, not a platform team
A CTO should read a software modernization roadmap the same way an investor reads an acquisition memo. Where’s the downside? What assumptions break first? Which systems deserve more capital, and which ones should be contained or retired?
Use a blunt standard:
| Decision lens | Bad roadmap behavior | Defensible roadmap behavior |
|---|---|---|
| Business case | “Modernize because the stack is old” | Tie work to specific business outcomes |
| Risk treatment | Assume issues will be found during delivery | Name technical and operational failure modes up front |
| Sequencing | Start with the biggest, most visible system | Start where value is clear and blast radius is manageable |
| Governance | Quarterly status theater | Measurable gates with pause and stop criteria |
A roadmap that can’t justify why a system should remain in the portfolio has no business prescribing its future architecture.
The Modernization Kill Switch When Not to Modernize
The smartest modernization decision is often a refusal. Not forever. Just until the facts support action.
Data shows 67% of modernization projects fail due to technical pitfalls, and existing guides rarely give CTOs a defensible no-go framework, including when sunsetting beats migration or how to price risks like COMP-3 decimal precision loss in COBOL migrations (Martinelli on software modernization roadmaps).
Sometimes the best modernization decision is to stop before you start. This checklist helps identify projects doomed from the outset.

Five kill-switch conditions
1. The system is ugly but economically stable
If the platform is brittle yet cheap to run, serves a shrinking user base, and isn’t blocking strategic work, don’t force a modernization program just because the code offends your standards. Retain it, isolate it, and spend elsewhere.
That’s not laziness. It’s portfolio discipline.
2. You can’t state the return in operational terms
“No clear ROI” means more than weak finance slides. It means you can’t explain what the business gets in concrete terms: reduced incident burden, faster release flow, stronger security controls, cleaner data handling, or decommissioned infrastructure.
If all you’ve got is “cloud-native flexibility,” you don’t have a business case.
3. You’re about to preserve broken business logic in a new stack
A surprising number of modernization efforts fail because the technology changes while the underlying workflow remains irrational. Teams migrate every exception, workaround, and approval bottleneck into new services and APIs, then act surprised when delivery doesn’t improve.
Kill or pause the project if the process owner can’t simplify the process before engineering starts.
Practical rule: Never modernize a workflow you haven’t challenged. You’ll only automate dysfunction.
4. Critical stakeholders aren’t aligned on what must not break
Stakeholder misalignment is not a communication issue. It’s a delivery risk. If finance, operations, compliance, and product disagree on what data, controls, or customer behaviors are essential, the program will drift into rework and conflict.
Pause until you have written decision rights.
5. The skills gap is real and immediate
If the team lacks the capability to run the target stack, operate CI/CD, handle observability, or validate data conversion, the roadmap is fantasy. This matters even more in legacy-heavy environments where the old system depended on tacit knowledge held by a handful of specialists.
A kill-switch matrix you can use in steering review
Use this before approving funding beyond discovery.
| Condition | If yes | Decision |
|---|---|---|
| Low business growth, low user expansion, low strategic relevance | The system isn’t a future differentiator | Retain or sunset |
| Benefits are described vaguely | No measurable operating or business improvement | Pause |
| Core workflows are convoluted or disputed | New stack will encode old mistakes | Redesign process first |
| Data conversion has high integrity risk | Financial or operational errors are unacceptable | Run proof first or stop |
| Target-state skills are missing | Team can’t safely deliver or operate | Upskill first or narrow scope |
Where sunsetting beats modernization
Sunsetting wins when the platform’s remaining business life is shorter than the organizational pain of moving it. That usually shows up in systems with declining usage, duplicate capabilities, or reporting-only workloads that can be archived and accessed through simpler means.
It also applies when dependency chains are so tangled that extraction costs more than controlled retirement. In those cases, your software modernization roadmap should document a decommission path, not a migration path.
A CTO needs permission to say no. Without that, every old system becomes a candidate for investment, and your portfolio fills with expensive regret.
A 4-Lens Assessment to Quantify Risk and Value
Once a system survives the kill switch, assess it through four lenses. Not one. A technical audit alone misses the reasons programs fail in finance reviews, operating reviews, and post-cutover support.
The useful model is Technical Viability, Business Value Alignment, Organizational Readiness, and Financial Impact.
A solid roadmap links modernization work to business outcomes. Strong teams don’t say “improve performance.” They define outcomes like reducing checkout load time from five seconds to two seconds. Leaders also prioritize cybersecurity, data management, and cloud migration, which means your assessment can’t be one-dimensional (application modernization roadmap guidance from CHI Software).
If you need a structured starting point for discovery, this legacy system risk assessment guide is a practical reference for building the inventory and dependency view.
Lens one: Technical viability
This is not a code quality score.
You need to understand dependency density, release friction, integration patterns, data coupling, testability, and operational fragility. Review codebase hotspots, performance logs, deployment paths, and interfaces with external systems. If one batch job, one file format, or one undocumented interface can break downstream reporting or customer workflows, that belongs in the first-page risk register.
Ask questions like:
- Where are the hidden dependencies?
- What data contracts are poorly documented?
- Which interfaces can’t tolerate schema drift or timing changes?
- What part of the stack only one engineer understands?
Lens two: Business value alignment
A system can be technically miserable and still worth preserving. Another can be elegant and still irrelevant.
Tie the platform to business outcomes that matter now. Security control improvements. Better data management. Faster product change. Reduced infrastructure drag. Cleaner compliance evidence. If the system doesn’t support a current strategic objective, it drops in priority no matter how emotionally attached the organization is to fixing it.
Reduce the distance between a technical milestone and a business result. If you can’t, the work isn’t ready for funding.
Lens three: Organizational readiness
Many roadmaps become dishonest when they assume the current team can deliver and operate the future state because the org chart says “platform,” “cloud,” or “DevOps.”
Assess real readiness instead:
- Skill coverage: Who can build it, run it, secure it, and troubleshoot it?
- Decision velocity: How quickly can product, architecture, and compliance resolve tradeoffs?
- Change tolerance: Can the business absorb phased releases, retraining, and process changes?
- Ownership clarity: Who owns post-cutover incidents and technical debt retirement?
If ownership is fuzzy before migration, it will be chaotic after migration.
Lens four: Financial impact
This is broader than implementation cost. Include run-state economics, support burden, internal time, cutover risk, rework probability, and the cost of delay on other priorities.
Use this lens to compare realistic alternatives:
| Option | Financial posture | Typical use |
|---|---|---|
| Retain | Lowest immediate spend, ongoing drag | Stable systems with acceptable risk |
| Replatform | Moderate spend, targeted efficiency | Viable core logic with outdated runtime or infra |
| Refactor or rearchitect | Higher spend, bigger operating change | Strategic systems with clear future value |
| Sunset | Spend shifts to retirement and data handling | Declining or redundant systems |
A software modernization roadmap becomes defensible when all four lenses agree. If one lens says no, don’t bury it in appendix slides. Escalate it.
Setting Unforgiving Metrics KPIs That Survive Scrutiny
Most modernization KPIs are too soft to govern anything. “Improve reliability.” “Increase agility.” “Boost developer productivity.” Those aren’t metrics. They’re aspirations.
Use metrics that can trigger intervention.
A critical roadmap step is robust monitoring. Effective programs track KPIs such as system uptime above 99.5%, development velocity measured in story points per sprint with ±15% variance, and business impacts like 15–35% year-over-year infrastructure savings. That matters because 67% of efforts derail due to unmonitored deviations (LeanIX application modernization roadmap guidance).
Track leading indicators before lagging outcomes
Lagging indicators tell you whether the migration eventually worked. Leading indicators tell you whether it’s going off the rails now.
Use both.
| Metric Category | KPI | Target | Indicator Type |
|---|---|---|---|
| System performance | System uptime | >99.5% | Lagging |
| Development execution | Story points per sprint variance | ±15% variance | Leading |
| Quality and stability | Post-deployment defect rate | <5% | Lagging |
| Business impact | Infrastructure savings | 15–35% YoY | Lagging |
Those aren’t vanity numbers. They expose whether the team can deliver predictably, whether production quality is holding, and whether the business case is materializing.
Ban vague goals from steering reviews
If a program says it will “improve performance,” force specificity. Use the operating example from earlier: reducing checkout load time from five seconds to two seconds. That’s governable. It links engineering work to user experience and commercial outcome.
Apply the same standard elsewhere:
- Security posture: Define which controls, exposures, or audit pain points the work removes.
- Data management: Specify which data quality, lineage, or access problems get fixed.
- Cloud migration: State what operating capability improves, not just where workloads move.
If a KPI can’t embarrass someone in a monthly review, it won’t change behavior.
Build the dashboard for intervention, not reporting theater
A useful dashboard does three things. It shows trend, threshold, and owner.
Don’t overload executives with raw observability feeds. Give them the decision surface:
- Red thresholds: Explicit breach conditions for uptime, defects, or delivery stability.
- Owner by metric: One accountable leader for each KPI.
- Action state: Continue, intervene, pause, or rescope.
Run monthly tactical reviews against those metrics. If development velocity blows past the allowed variance or defect rates drift, adjust scope before the roadmap collapses under optimistic assumptions.
Separate health metrics from outcome metrics
Teams often confuse system telemetry with modernization success. CPU curves and deployment counts matter, but they are not the business case.
Use a simple rule. Every technical KPI should map to one of these questions:
- Does it reduce operating risk?
- Does it improve delivery reliability?
- Does it produce a measurable business effect?
If the answer is no, drop it from the executive dashboard and keep it at the engineering level.
Mapping the Migration From Big Bang Failures to Iterative Wins
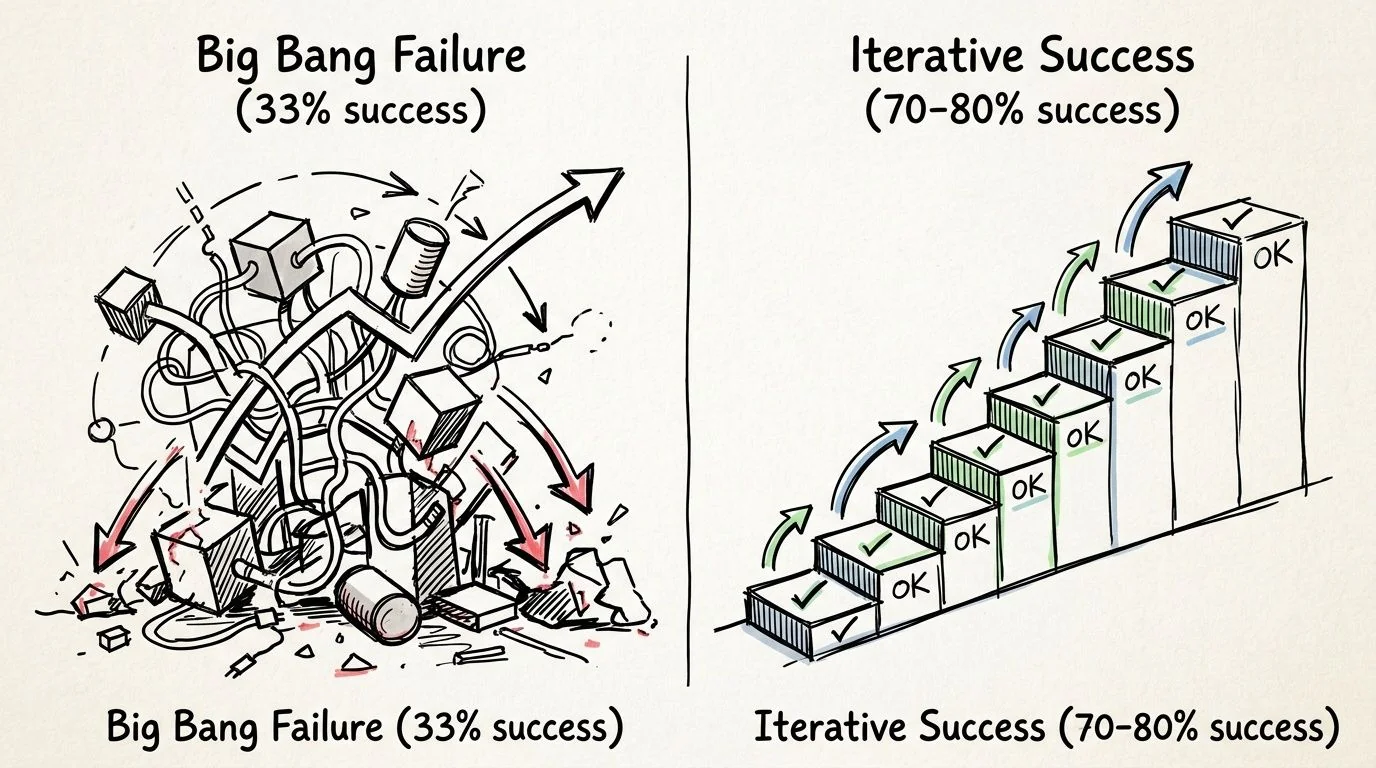
The worst migration strategy is still the most tempting. Big-bang replacement looks decisive, easy to explain, and clean on a roadmap. It also fails far too often.
A proven modernization roadmap favors iterative execution. That approach reaches 70–80% success rates, compared with 33% for big-bang efforts, and can deliver up to 74% lower hardware, software, and staff costs when teams start with small pilots and scale incrementally (Evinent on application modernization roadmap execution).
Choose the migration pattern by risk, not fashion
A rehost, replatform, refactor, or replace decision should come from the assessment. Not from the cloud team’s preferences and not from a board deck that wants the word “AI” near the architecture diagram.
Here’s the practical view:
| Pattern | What it’s good for | What usually goes wrong |
|---|---|---|
| Rehost | Fast infrastructure exit | Carries old performance and operating flaws into the new environment |
| Replatform | Moderate improvement without rewriting core logic | Underestimates integration and runtime constraints |
| Refactor or rearchitect | Long-term agility for strategic systems | Scope expands when boundaries were never defined |
| Replace | Escaping dead-end software | Business fit and process parity are often overestimated |
The common error is overcommitting to refactor or replace before the organization proves it can execute smaller cuts safely.
Start with a pilot that can teach you something
Your first move should be a low-risk, high-learning pilot. Pick an application or module with real business relevance but acceptable blast radius. Use it to validate deployment automation, data movement, rollback logic, support ownership, and user acceptance.
That’s where teams should borrow from broader product planning discipline. Refact’s product roadmap insights are useful here because they stress sequencing, validation, and learning loops instead of roadmap theater.
For teams building a phased approach around legacy constraints, this guide to incremental legacy modernization is aligned with the same principle. Prove the path before scaling the spend.
Use a strangler approach whenever boundaries allow it
If the system architecture gives you even partial seams, exploit them. Put a facade in front of the legacy platform, route narrowly defined functions to modern services, and expand over time.
That reduces two risks at once. It limits cutover shock, and it exposes process and data issues earlier.
A practical walkthrough is worth seeing before you decide sequencing and architecture boundaries:
What iterative execution changes operationally
An iterative software modernization roadmap forces discipline:
- Pilot first: Validate testing, deployment, and rollback under real conditions.
- Scale in slices: Move a capability, not an empire.
- Keep feedback tight: User reaction and support tickets should influence the next increment.
- Review architecture quarterly: Roadmaps that don’t adapt become obsolete.
Big-bang programs fail because they hide risk until the point of maximum commitment. Iterative programs surface risk while it’s still cheap to correct.
Budgeting for Reality and Selecting the Right Partners
Most modernization budgets are fiction for a different reason. They price the migration work, but not the organizational disruption required to absorb it.
A real budget must include internal engineering time, architecture review, security review, test automation, release management, data validation, training, temporary productivity loss, and contingency for ugly legacy surprises. If your estimate only includes vendor effort and cloud spend, it’s not a business case. It’s a partial invoice.
Build a total cost of modernization model
Use four buckets.
Delivery cost. External services, internal engineering, architecture, QA, and program management.
Transition cost. Dual running periods, cutover support, retraining, and process adaptation across operations, compliance, and product teams.
Risk reserve. Budget held for dependency discovery, data issues, rework, and rollback scenarios.
Run-state cost. The cost to operate the target platform after go-live, including tooling, support coverage, observability, and security operations.
A budget that ignores transition and run-state economics tends to approve projects that look affordable but cost more after modernization than before.
Cheap migration plans often create expensive operating models.
Partner selection should feel like risk underwriting
Don’t run a generic RFP and assume references solve the problem. Sales teams are polished. Delivery teams determine your outcome.
When evaluating partners, insist on evidence in five areas:
- Relevant migration path experience: Mainframe, Java monolith, Oracle Forms, custom .NET estate, data platform, or security stack. Specificity matters.
- Team continuity: Ask who will deliver, not who appears in the pitch.
- Failure transparency: Request examples of troubled programs and what the partner changed.
- Validation method: How they handle dependency mapping, data integrity checks, rollback design, and production cutover.
- Commercial alignment: Tie payment and governance to measurable milestones, not vague effort consumption.
This is the point where market intelligence is useful. Modernization Intel tracks implementation partners across migration paths and focuses on failure analysis, cost transparency, partner specialization, and when not to buy. That’s a more useful input than generic analyst positioning if you’re trying to understand execution risk rather than branding.
Contract for outcomes, not motion
If the statement of work rewards activity, you’ll get activity. Contract around gates that matter:
| Contract area | What to require |
|---|---|
| Discovery | Validated dependency map, risk register, and recommendation set |
| Pilot | Working slice in production-like conditions with rollback proof |
| Scale phase | Defined KPIs, release cadence, and ownership model |
| Cutover | Acceptance criteria tied to business continuity and support readiness |
You also need a termination path. If the partner can’t meet quality, transparency, or milestone discipline, your contract should let you stop without subsidizing failure.
The right roadmap has a stop clause
This is the final test of a mature software modernization roadmap. It doesn’t just say what you’ll modernize, how you’ll migrate, and which partner you’ll hire.
It states the conditions under which you will pause, narrow, or stop.
That’s the difference between disciplined transformation and expensive enthusiasm.
If you’re building a software modernization roadmap now, do three things this quarter. Write the kill-switch criteria before funding delivery. Score every target system through the four assessment lenses. Then approve only one pilot that has measurable KPIs, explicit rollback logic, and a named owner for post-cutover operations.
That sequence won’t make the roadmap more inspiring. It will make it more defensible.