
A Pragmatic SOC Modernization Roadmap for Enterprise Leaders
A SOC modernization roadmap is a strategic plan for dismantling a reactive, legacy-based Security Operations Center and replacing it with a proactive, scalable security architecture. The objective is to eliminate technical debt, bypass the legacy skills gap, and build a defensible posture using cloud-native platforms, intelligent automation, and AI-driven analytics. This is not about incremental upgrades; it’s about a fundamental re-architecture of how security operations are performed.
Your Legacy SOC Is an Active Vulnerability

Your Security Operations Center is running on fragile, outdated systems that are a clear and present danger to the business. This is not about adopting new technology for its own sake; it’s about confronting the collision of three systemic crises: a rapidly shrinking talent pool for legacy systems, unsustainable operational costs, and security tools that are outmatched by modern attack vectors.
The “if it isn’t broken, don’t fix it” mindset is a direct path to a major security breach. Your accumulated technical debt is no longer a balance sheet liability—it’s an actively exploitable attack surface.
The Quantifiable Cost of Inaction
The core problem is that your existing security infrastructure was never designed for current attack velocity or data volumes. Monolithic SIEMs and log processors cannot scale, lack native integration with modern threat intelligence, and fail to parse cloud-native data formats. These systems are not just slow; they are fundamentally incompatible with the security posture required to defend a modern enterprise.
The constant evolution of threats, such as the rising threat of infostealer malware, makes this an urgent operational risk. Legacy tools cannot adapt, guaranteeing you remain perpetually one step behind adversaries.
A SOC modernization roadmap is not an optional upgrade—it is an urgent risk mitigation strategy. The financial and reputational cost of a breach enabled by outdated technology dwarfs the investment required to modernize.
This technical challenge is compounded by a human capital crisis. Modernizing is also a strategic hedge against the skills apocalypse for legacy systems. By 2026, the global pool of COBOL developers will shrink to just 220,000. Their average age is 58.3 years, with 92% on track to retire by 2030. With universities having dropped COBOL from curricula in the early 2000s, 47% of organizations already cannot fill these roles. This is a current, not future, problem.
Decision Matrix: Prioritizing Modernization Drivers
Not all legacy risks are equal. A structured approach is required to identify which pain points pose the most immediate threat. This decision matrix quantifies and prioritizes the drivers for your SOC modernization roadmap by weighing technical fragility against business impact, moving the conversation from abstract concerns to a data-driven action plan.
Score each driver on a scale of 1-5 for both Technical Risk (fragility, limitations) and Business Impact (operational or financial fallout from failure). Multiplying these yields an Urgency Score to dictate priorities.
| Modernization Driver | Technical Risk (1-5) | Business Impact (1-5) | Urgency Score (Risk x Impact) |
|---|---|---|---|
| Legacy SIEM Inability to Scale | 5 | 5 | 25 |
| Lack of Cloud-Native Integration | 4 | 5 | 20 |
| Dependence on Retiring Talent | 5 | 3 | 15 |
| High False Positive Rate | 3 | 4 | 12 |
| Excessive Legacy Licensing Costs | 2 | 3 | 6 |
This exercise immediately clarifies focus. A high score, like the SIEM’s inability to scale, signals a critical failure point demanding immediate action. Lower scores, while still relevant, can be addressed in subsequent phases.
Conduct a Brutally Honest Security Operations Assessment
Before creating a roadmap, you need an accurate map of your current location. This demands an unvarnished, evidence-based view of your security operations. A successful modernization begins with a rigorous assessment that dissects not just what tools you have, but how work is actually performed and where legacy technology creates unacceptable risk and inefficiency. The goal is to establish a quantifiable baseline of your SOC’s effectiveness—or lack thereof. Without this data, your roadmap is merely a shopping list.
Mapping Current-State Capabilities and Dependencies
Trace the lifecycle of an alert, from log generation to analyst action. The objective is to identify every brittle, legacy component that injects latency or creates blind spots in that chain. For example, a critical alert for suspicious mainframe activity that depends on a nightly COBOL batch job to extract security logs introduces a 12- to 24-hour delay in your response. In the context of a ransomware attack, that delay is a catastrophic failure.
This requires moving beyond high-level architecture diagrams to document specific data sources, fragile ingestion pipelines, hard-coded detection logic, and manual response playbooks tied to each legacy component.
A successful assessment produces a detailed map of operational workflows that explicitly links security outcomes to the underlying technology, exposing every weak link in the chain. An assessment that only produces a tool inventory has failed.
Checklist: Identifying Specific Legacy Failure Points
Use this checklist to guide the investigation. It focuses on common failure patterns in legacy-dependent SOCs and translates technical debt into measurable operational drag. A superficial audit that ignores deep-seated architectural problems will doom the modernization project from the start.
- Brittle Data Pipelines: Are you dependent on nightly batch jobs or custom scripts for security data movement? Document the exact latency. An eight-hour delay in log ingestion is a critical failure, not a minor inconvenience.
- Hard-Coded Detection Logic: Is core detection logic embedded within monolithic applications (e.g., COBOL programs)? This makes tuning rules nearly impossible and prevents adaptation to new attacker TTPs. This is a major red flag.
- Outdated Protocol Dependencies: Do critical systems rely on legacy protocols like SNA or X.25? These lack modern security controls and make direct integration with cloud-native monitoring tools impossible.
- Lack of API-Driven Response: Can your team automate response actions (e.g., blocking an IP, isolating a host) via an API call, or does it require manual login to a legacy terminal? The absence of automation APIs directly increases Mean Time to Respond (MTTR).
- Manual Correlation Overhead: Quantify the analyst time wasted manually correlating data from disparate legacy systems. If an analyst must open three separate green-screen terminals to investigate one alert, that inefficiency is a direct and unnecessary salary cost.
- Inability to Process Modern Data: Can your legacy SIEM parse and analyze logs from cloud services, serverless functions, or Kubernetes clusters? If not, you have a massive and unacceptable visibility gap in your most modern environments.
Completing this process provides a precise, evidence-based case for change, quantifying the operational drag and security risk created by each legacy component. This detailed map is the essential prerequisite for designing a future-state architecture.
Designing the Future-State SOC Architecture
The architectural decisions made at this stage will dictate your security capabilities, budget, and operational tempo for the next decade. There is no single correct architecture; the optimal path depends on your risk profile, existing technical debt, and strategic objectives. We will analyze the three primary target-state models: Rehost, Refactor, and Rebuild. Each presents a different trade-off between speed, cost, and capability uplift.
Rehost: The Lift-and-Shift Model
Rehosting involves lifting existing SIEM and other security tools and shifting them to a cloud infrastructure provider. The core application logic remains unchanged; you are merely swapping on-premises data centers for IaaS.
This approach is viable when the primary driver is exiting the data center business or shedding hardware maintenance overhead quickly. However, this model does almost nothing to remediate the underlying limitations of legacy security tools. Your analysts will execute the same inefficient workflows, just on rented servers.
Refactor: The Reshape-and-Integrate Model
Refactoring is an intermediate strategy. It involves containerizing valuable pieces of legacy security logic and exposing them via modern APIs. For example, a battle-tested custom correlation engine can be wrapped in a container and integrated into a cloud-native security analytics platform.
This preserves unique, high-value detection logic while breaking free from a rigid, monolithic architecture. It enables a phased modernization, allowing component-by-component replacement without a high-risk “big bang” cutover. Refactoring is optimal for organizations with significant investment in custom security logic that need to integrate with modern platforms for scale and automated response.
Rebuild: The Cloud-Native Replacement Model
Rebuilding is the most transformative approach. It entails completely replacing legacy systems with a cloud-native security data platform, such as Microsoft Sentinel, Google Chronicle, or a custom solution on a data platform like Snowflake. This is not just a SIEM replacement; it is an architectural shift to a flexible, scalable platform designed for modern data volumes and analytics.
This model enables a step-change in security capabilities, unlocking AI-driven threat detection, fully automated response, and unified visibility across hybrid environments. A rebuild is the ideal opportunity to embed modern security frameworks like a Zero Trust architecture design. As you design this future state, understanding the differences between MDR and SOC models is critical to align services and architecture. While the upfront investment is highest, the long-term ROI from reduced operational overhead and improved security posture is substantial.
The cloud migration market, a core enabler of SOC modernization, is projected to grow from $232.51 billion in 2024 to $806.41 billion by 2029, a 28.24% CAGR. This reflects a massive enterprise shift away from aging security stacks toward scalable, AI-ready platforms. Over 52% of organizations are already moving COBOL applications—which often power legacy SOC data pipelines—to AWS for the elasticity required for real-time threat hunting (rocketsoftware.com).
Decision Framework: Choosing Your Target State
The choice between Rehost, Refactor, and Rebuild is a strategic business decision. This table outlines the trade-offs to align architectural paths with business goals.
A “Rebuild” is not always the correct answer. A poorly executed Rebuild project, driven by technology acquisition rather than a clear business case, has a failure rate exceeding 50%. A pragmatic Refactor often delivers 80% of the value at 40% of the risk.
| Model | Primary Goal | Typical Timeline | Estimated Cost Range | Key Technical Risk |
|---|---|---|---|---|
| Rehost | Infrastructure Cost Savings | 3-6 Months | Low ($100k - $500k) | Retaining legacy technical debt |
| Refactor | Incremental Modernization | 9-18 Months | Medium ($500k - $2M) | API integration complexity |
| Rebuild | Capability Transformation | 18-36+ Months | High ($2M - $10M+) | High execution risk and scope creep |
Your final SOC modernization roadmap will likely be a hybrid. You might Rebuild your core analytics platform, Refactor a critical legacy fraud detection engine, and Rehost a niche compliance logging tool. The key is a deliberate, data-driven decision for each component of your security architecture.
Execution: The Pilot and Phased Rollout
A “big bang” migration is a high-risk, all-at-once cutover with a documented failure rate exceeding 70% for complex IT projects. A credible SOC modernization roadmap de-risks execution with a disciplined pilot program, followed by a phased, wave-based rollout. This approach builds momentum, proves value at each stage, and secures stakeholder buy-in with tangible results, all while avoiding disruption to live security monitoring.
Scoping the Pilot Project
The pilot’s purpose is to prove the target architecture works with your data, your people, and your processes. Scope it tightly. Select a single, non-critical but representative data source, such as logs from a specific cloud service (e.g., AWS S3 bucket) or a low-traffic internal web application.
Next, implement one well-understood detection use case. A classic example is detecting “impossible travel” from user authentication logs. This use case is sufficiently complex to test the entire chain—ingestion, parsing, correlation, and alerting—but is not so obscure that success is difficult to measure.
The pilot’s primary objective is to validate the entire operational workflow. Success is defined as an analyst receiving an alert from the pilot system, investigating it with the new tools, and resolving it faster and more accurately than in the legacy environment.
To achieve this, establishing a “shadow SOC” is mandatory.
Proving Value with a Shadow SOC
The shadow SOC runs the pilot platform in parallel with the legacy system, ingesting the exact same data source. This is non-negotiable, as it creates a direct, apples-to-apples comparison of detection quality, alert fidelity, and analyst workflow.
During this phase, analysts work alerts from both systems. This dual-track operation serves two critical functions:
- Validation: Directly compare alerts. Does the new system detect threats the old one misses? Is alert quality higher, with fewer false positives? This provides hard data, not vendor promises.
- Readiness: The team gains hands-on experience with the new platform in a controlled environment. This is the most effective form of training and a core part of any legitimate cloud readiness assessment.
This parallel operation prevents disruption to live security monitoring while generating irrefutable evidence of the new architecture’s value—the data required to secure buy-in for the full rollout.
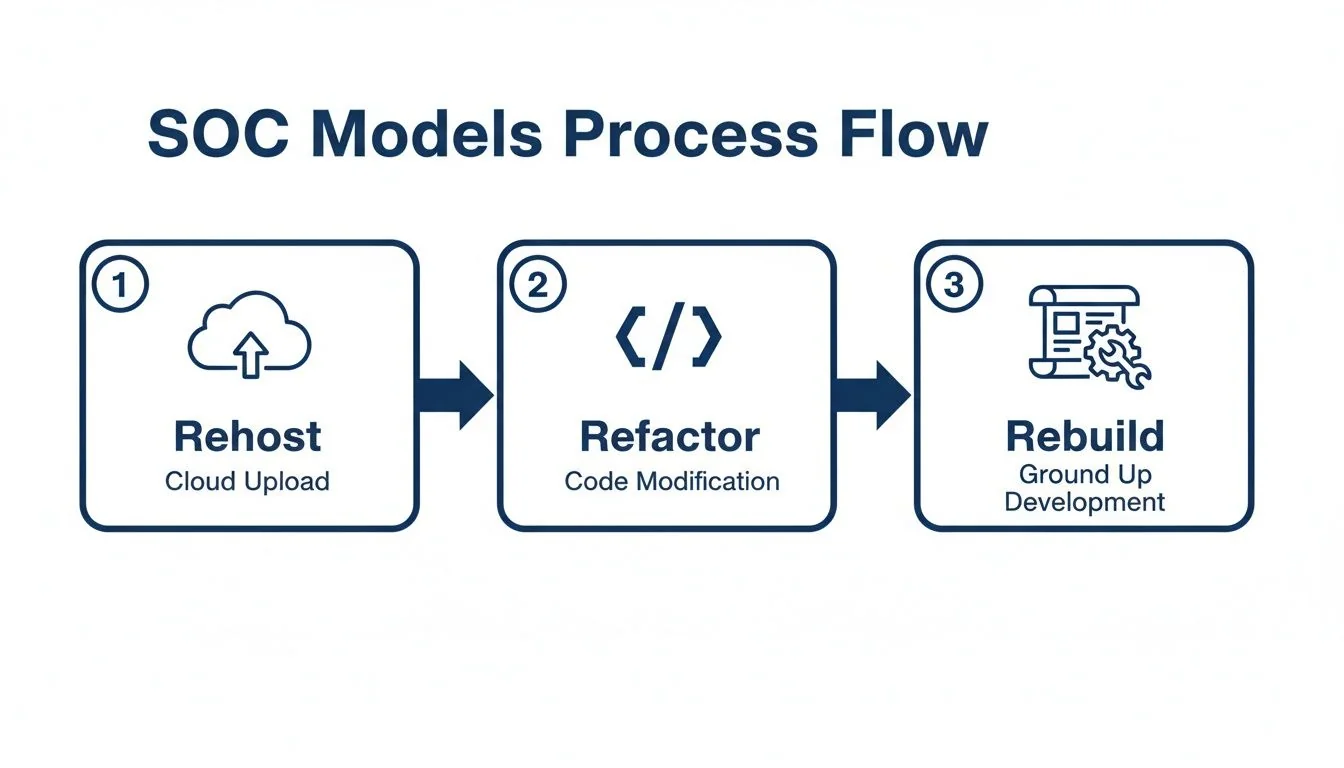
This flow illustrates the increasing commitment and transformative potential from Rehost to Rebuild. The pilot is designed to validate how far along this path you must travel to achieve the required business value.
Planning a Phased, Wave-Based Rollout
Following a successful pilot, begin the broader migration. This is an iterative process. Group data sources and use cases into logical waves, prioritized by risk and business impact.
A proven rollout strategy includes:
- Data Source Waves: Migrate data sources in logical bundles. Wave 1: All cloud infrastructure logs. Wave 2: All endpoint detection and response (EDR) data. Wave 3: Complex legacy application logs.
- Playbook Translation: Systematically migrate and refactor incident response playbooks. This is an opportunity to embed new automation capabilities and eliminate manual steps.
- Analyst Training Cycles: Align training with the rollout schedule. As each new data source and use case goes live, conduct focused, hands-on training for the analyst team.
This methodical, wave-based approach avoids overwhelming the team, builds confidence in the new platform, and delivers incremental value throughout the project, turning a monolithic migration into a series of manageable, low-risk wins.
Next Steps: Building the Business Case
A modernized SOC is a strategic investment in business resilience. Securing budget requires a financial case that ties operational improvements directly to quantifiable business value. Move beyond tactical security acronyms and build a case grounded in cost reduction, risk mitigation, and operational efficiency.
Translate Technical Wins into Financial Metrics
Traditional SOC metrics like Mean Time to Detect (MTTD) and Mean Time to Respond (MTTR) are essential for operations but meaningless in the boardroom. Translate these wins into financial terms. Slashing threat dwell time from 90 days to 10 days directly reduces the potential financial blast radius from data theft, business disruption, and regulatory fines.
The business case must follow a clear formula: ROI = (Cost Reduction + Risk Mitigation Value) / Modernization Investment. Your task is to populate each variable with credible, defensible data.
Quantify Cost Reduction and Avoidance
This is the most straightforward component of the ROI calculation.
- Decommission Legacy Infrastructure: Calculate annual savings from eliminating mainframe MIPS, hardware maintenance contracts, and data center floor space.
- Eliminate Legacy Software Licenses: Sum the annual licensing and support fees for legacy SIEMs, log management tools, and other replaced software.
- Automate Manual Labor: Quantify analyst-hours wasted on manual tasks that will be automated. A reduction of 4,000 analyst-hours per year spent on false positive triage, at a blended rate of $75/hour, translates to $300,000 in direct operational savings.
Data shows the ROI on mainframe modernization, a core component for many legacy SOCs, has recently doubled. Average project spending dropped from $9.1 million to $7.2 million, while financial returns skyrocketed to 362% for migrations and 297% for cloud integrations. Case studies confirm 40-60% operational cost reductions in the first year alone (softwaremodernizationservices.com).
Calculate the Financial Value of Risk Reduction
Quantifying risk reduction is essential for the complete ROI picture. Project the value of an improved security posture by calculating the reduction in breach probability and potential impact using a model like Annualized Loss Expectancy (ALE).
Example: Ransomware Attack Risk
- Single Loss Expectancy (SLE): Estimate the total cost of a successful ransomware attack at $5 million (downtime, recovery, fines).
- Annual Rate of Occurrence (ARO) - Before Modernization: Based on current vulnerabilities, assume a 10% annual probability. ALE = $500,000 ($5M x 10%).
- Annual Rate of Occurrence (ARO) - After Modernization: With the new architecture’s enhanced detection and automated response, project a reduced probability of 2%. New ALE = $100,000 ($5M x 2%).
This single scenario demonstrates $400,000 in annualized risk reduction value. Modeling this across several high-impact threats builds a powerful, data-driven argument that a SOC modernization roadmap is not a cost center—it is a strategic investment in business continuity.
Your SOC Modernization Questions, Answered
A SOC modernization is a high-stakes, multi-year initiative. The questions asked at the outset determine success or failure. Here are the most critical questions from CTOs and VPs of Engineering, with direct answers based on real-world projects.
What Is the Single Biggest Mistake in a SOC Modernization Roadmap?
The most common and costly failure is believing this is a technology replacement project. It is not. The fatal error is swapping an old SIEM for a new one without fundamentally re-engineering the legacy processes and data strategy that made the old one ineffective.
Too many leaders fixate on the tool and underestimate the complexity of migrating a decade of fragile, custom detection logic and battle-scarred response playbooks. This “lift-and-shift” approach results in a more expensive, cloud-hosted version of the same broken SOC, failing to unlock any of the promised speed or automation.
If your primary success metric is “new SIEM deployed,” the project has already failed. The goal is a new capability, not a new tool. A valid goal is: “Reduce manual alert triage by 50%” or “Cut threat dwell time from 90 days to under 15.”
How Long Does This Actually Take?
A full-scale enterprise SOC modernization is not a short-term project. Be deeply skeptical of any partner promising a complete overhaul in less than a year. A realistic timeline is 18 to 36 months, executed as a series of distinct phases.
- Phase 1: Assessment and Design (3-6 months): Dissect the current state and design the future architecture. Rushing this step guarantees failure.
- Phase 2: Pilot Project (3-4 months): A tightly-scoped proof-of-concept to validate the new architecture and operational workflows with a non-critical, high-volume data source.
- Phase 3: Phased Rollout (12-24 months): The execution phase. Migrate data sources, use cases, and playbooks in manageable, iterative waves.
This phased approach builds momentum, demonstrates incremental value, and avoids the astronomical failure rates of “big bang” cutovers.
How Do You Select the Right Modernization Partner?
Look past generic “cloud certified” badges. You need a partner with demonstrable experience in security data pipelines and, critically, integration with the specific legacy systems you are escaping.
Demand proof. Ask for case studies of migrations from your specific legacy SIEM or mainframe environment. Scrutinize their methodology for translating security use cases, not just moving log data. A major red flag is a partner who pushes a single vendor’s product before conducting a thorough, platform-agnostic assessment of your requirements. Finally, demand radical transparency: ask for their data on project failure rates and average cost overruns. A partner who cannot or will not answer has something to hide.
When Does It Make Sense Not to Modernize?
Modernization is not always the correct decision. The objective is to reduce risk and improve capability, not to adopt new technology. It makes zero sense to modernize a highly customized, stable legacy application that has a low business impact and no requirement to integrate with modern systems.
A classic example is a niche compliance reporting tool hard-wired to a mainframe process that runs quarterly. It is functional and isolated. The business requires its output, but it has no bearing on real-time security posture.
The cost and risk of rewriting such an application would vastly outweigh any benefit. For these specific cases, containment is the superior strategy. Isolate it, secure the perimeter around it, and focus the modernization budget on high-value, high-risk components of your security architecture where speed and integration are critical.