
Mastering API Versioning Strategy Migration
Most API version migrations don’t fail because the team picked the wrong versioning style. They fail because the team treated the work like a routing change instead of a customer contract renegotiation. The evidence points in that direction. Teams usually understand URI, header, query, and hybrid versioning patterns, but struggle with retirement planning, maintenance windows, migration support, and the communication loop required to remove old behavior without breaking trust, as Redocly notes in its guidance on API versioning best practices.
That distinction matters for modernization programs. Once an API becomes business-critical, versioning stops being a code organization choice and becomes a control system for change. The core effort is coexistence, backward compatibility, traffic isolation, client communication, and eventually deprecation with enough operational discipline that nobody wakes up to a broken integration.
This is the part most guides underplay. Running old and new contracts in parallel costs engineering time, support time, test time, gateway time, and leadership attention. If you don’t plan those costs up front, the migration stalls, or worse, the old version never dies.
Your API Migration Is a Contract Negotiation Not a Tech Swap
An API migration becomes dangerous the moment you tell yourself it’s “just v2.”
Your consumers don’t experience your architecture diagram. They experience the contract. They built clients around request shapes, response schemas, field semantics, retry behavior, and undocumented quirks your team wishes didn’t matter. Change that unilaterally and you haven’t shipped a modernization. You’ve broken an agreement.

What senior teams get wrong
The common mistake is over-focusing on the mechanics of version placement and under-focusing on migration operations. That’s backwards. Consumers rarely care whether the version sits in the path or a header. They care whether their integration still works, whether the docs are accurate, and whether your deprecation schedule is credible.
Many teams can describe versioning patterns, but struggle with the migration program itself.
That gap is where trust erodes. Retirement planning has to exist from day one. Maintenance windows, migration support, and follow-up communication tied to actual usage monitoring aren’t optional extras. They’re part of the architecture when you’re executing API versioning strategy migration in a production environment.
Treat the migration like a managed commercial obligation
A useful framing is to run the migration under the same discipline you’d use for any external commitment:
- Define the contract boundary: Specify exactly what remains stable for existing consumers and what moves behind a new contract.
- Publish the migration path: Updated documentation, side-by-side examples, and explicit deprecation language reduce ambiguity.
- Support dual reality: Old and new versions must both behave as documented while clients move on their own schedules.
- Set removal conditions: Don’t retire based on optimism. Retire when monitoring confirms deprecated endpoints are no longer used.
The engineering work is still real. Routing, schema evolution, observability, test automation, and gateway rules all matter. But the business risk comes from forcing change faster than your consumers can absorb it.
If the migration is handled well, clients see competence. If it’s handled badly, they see instability.
First Decide If You Should Version at All
The most expensive version is the one you never needed to create.
A lot of teams jump straight into debates about /v2, custom headers, or media types. That’s premature. The first decision is whether the change requires a new version. Some changes should never become a versioned fork. They should be handled through additive evolution, tolerant clients, and disciplined compatibility rules.
Milan Jovanović puts it plainly in his piece on why API versioning should be your last resort: “Versioning is a compatibility tool. It is not a design strategy.” That line is worth repeating in design reviews because it cuts through a lot of avoidable complexity. The same article points to Stripe’s approach, where most changes are evolutionary and full version releases are reserved for significant breaking changes.

Use a versioning gate before you approve v2
Before anyone opens a new branch for a new public contract, force the proposal through a short decision gate.
| Question | If the answer is yes | What to do |
|---|---|---|
| Does the change remove or rename existing behavior? | Existing clients will break | Consider a new version |
| Can the change be added as new optional behavior? | Older clients can ignore it | Prefer additive evolution |
| Are you correcting a bad model that clients already depend on? | Contract drift already exists | Version only if compatibility shims won’t hold |
| Can you support two contracts operationally? | You need routing, tests, docs, support | Budget the coexistence work before approving |
| Is the consumer base large or hard to coordinate? | Forced upgrades will create churn | Favor migration paths with slower client adoption |
This sounds simple, but it stops a lot of bad decisions. Teams often version because they want a cleaner design, not because consumers need a clean break. Internal aesthetic improvement isn’t enough justification for multi-version support.
When not versioning is the better modernization move
In real systems, plenty of changes are safer as incremental evolution:
- Additive fields: Existing consumers ignore new optional response fields.
- New endpoints: New capabilities can live alongside stable ones without disturbing current integrations.
- Optional request parameters: You can introduce new behavior without changing the default contract.
- Behavior behind defaults: If old requests preserve old semantics, clients don’t need to move immediately.
Practical rule: If consumers can keep their current integration and still get correct behavior, don’t create a new version just because the backend changed.
The trap is thinking versioning reduces risk automatically. It doesn’t. It often moves risk from client breakage to platform sprawl. You still have to support two contracts, two test surfaces, two documentation sets, and two operational paths.
A simple approval checklist for executives and architects
Use this before greenlighting a new public version:
- Identify the exact breaking change. If nobody can describe the break precisely, the team probably hasn’t earned a new version.
- Prove additive evolution won’t work. Require examples, not opinions.
- List coexistence obligations. Documentation, support channels, monitoring, contract tests, routing rules, rollback paths.
- Set the retirement model up front. A version without a sunset plan is a liability from day one.
- Assign consumer ownership. Someone must own partner migration, not just backend delivery.
Versioning is sometimes necessary. But in strong modernization programs, it’s a controlled exception, not the default move.
Selecting a Versioning Model That Fits Your Architecture
Once you’ve decided a new version is justified, stop arguing in absolutes. There isn’t a universally correct versioning model. There is only the model that best fits your gateways, clients, caches, documentation workflows, and operating constraints.
The historical pattern is clear. As APIs became business-critical, teams moved from simple release numbering toward structured migration and deprecation practices. Over time, common practice converged on four main approaches: URI path versioning, query parameter versioning, header-based versioning, and hybrid approaches, as summarized by Moesif in its review of API versioning strategies for seamless integration. URI path versioning became especially popular because it makes the active version explicit, supports parallel hosting, and works well with caching. Moesif also highlights its adoption by major companies such as Facebook, Twitter, and Airbnb.
Use an architectural decision matrix
If you’re choosing a model for API versioning strategy migration, evaluate it against operational criteria instead of ideology.
| Strategy | Cacheability | Gateway Simplicity | Client Effort | Discoverability |
|---|---|---|---|---|
| URI path versioning | Strong. Version is explicit in the request path | Simple routing in most gateways | Low for most clients | High. Easy to see and document |
| Query parameter versioning | Weaker unless caches are configured carefully | Moderate. Routing rules can get messy | Moderate. Clients must pass version consistently | Medium. Visible, but easier to miss |
| Header-based versioning | Depends on careful proxy and cache handling | Moderate to high. More policy logic | Higher for simple browser clients, acceptable for SDKs | Lower. Version isn’t obvious from the URL |
| Hybrid approaches | Varies by implementation | Highest complexity | Highest risk of inconsistency | Can be confusing unless tightly governed |
What works in practice
URI path versioning works well when you need clarity, predictable routing, and easy coexistence. If your API gateway team needs low-friction traffic controls and your support team needs to identify versions quickly from logs and examples, path-based schemes are hard to beat.
Header-based versioning fits mature platforms with stronger client tooling. It keeps URLs cleaner, but it pushes more responsibility into SDKs, gateway policies, observability, and support workflows. If your consumers are browser-heavy or partner teams manually debugging requests, header-only strategies create friction.
Query parameter versioning is usually a compromise. It can be made to work, but teams often underestimate how much special handling it creates around routing, caching, and documentation consistency.
Match the strategy to the ecosystem you actually have
A healthcare platform integrating multiple contract-heavy systems has very different needs from an internal platform where one company owns all clients. If you’re modernizing clinical or research APIs, for example, interoperability work such as integrate FHIR R4 with OMOP workflows often benefits from highly explicit contract boundaries because multiple downstream consumers interpret schemas differently and migrate on different schedules.
The same principle shows up in legacy integration programs. If your modernization roadmap depends on exposing stable interfaces over older systems, this guide on API-led connectivity for legacy modernization is useful because it frames APIs as long-lived boundaries, not just transport wrappers.
Pick the versioning model that reduces surprises in routing, caching, and client support. You can tolerate aesthetic imperfections. You can’t tolerate operational ambiguity.
The bad choice isn’t usually “path versus header.” The bad choice is adopting a model your platform can’t monitor, document, and retire cleanly.
Implementing a Zero-Downtime Migration Rollout
The technical centerpiece of API versioning strategy migration is coexistence. Old and new contracts run at the same time, under load, with real consumers, while your team tries to prevent accidental drift. That’s where migrations get expensive and where weak execution shows up fast.
Gravitee’s guidance on API versioning best practices gets to the core problem: the greatest risk isn’t having multiple versions in theory. It’s the operational complexity of preserving backward compatibility while supporting parallel traffic. Every active version adds maintenance, testing, and support overhead. Gravitee also recommends clear policies on how many versions remain active to avoid version sprawl.
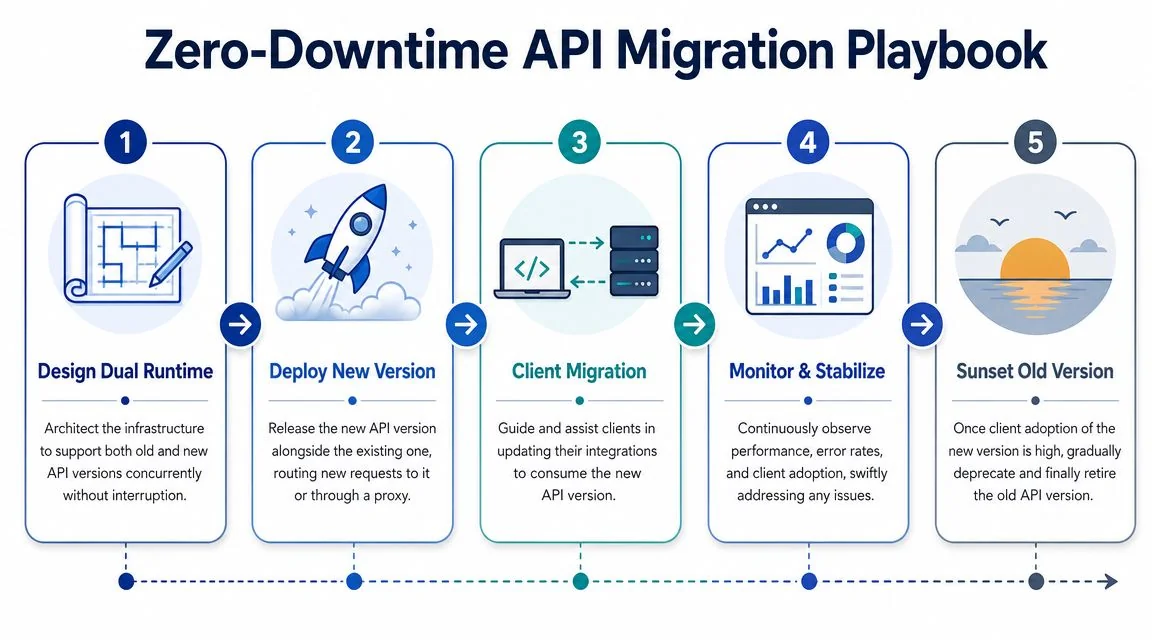
The rollout pattern that actually holds up
A durable rollout has five phases.
-
Design dual runtime support
Build the new version as a parallel contract, not as a risky in-place mutation. In practice that means version-aware routing in your API gateway, separate contract tests per version, and observability that can isolate old and new behavior. -
Deploy the new version beside the old one
Don’t force an immediate consumer cutover. Put both versions into production and validate them independently. Route internal consumers, test harnesses, or selected partner integrations first. -
Protect backward compatibility continuously Many teams often get sloppy with this. Gravitee notes the overhead problem. The stricter guidance comes from the verified material that points to unit tests and continuous integration as the enforcement mechanism for backward compatibility. Treat any schema drift, response-contract change, or request-shape regression in a supported version as a release blocker.
-
Instrument by version
Aggregate metrics aren’t enough. You need version-specific logs, alerts, dashboards, and rollback options. If v2 starts failing but the total API error picture looks flat because v1 is healthy, you’ll miss the issue until customers report it. -
Control version lifespan from the beginning
Decide how many versions can be live at once, who approves exceptions, and what sunset policy governs removal. Otherwise your temporary coexistence model becomes permanent architecture.
The non-negotiable test boundary
Release blocker: If a change alters a supported request or response contract outside an explicit new version, it doesn’t ship.
That standard is blunt because it needs to be. Teams often say they’re preserving backward compatibility when they’re really preserving “most” of it. Consumers don’t care about intent. They care whether the integration still deserializes, validates, and behaves correctly.
A practical implementation usually includes:
- Contract tests: Validate request and response schemas for each supported version.
- Gateway regression checks: Confirm routing rules, auth policies, and transformations are version-scoped.
- Version-specific monitoring: Break down latency, error signatures, and support tickets by version.
- Rollback controls: Make rollback possible without taking both versions down together.
To ground the rollout in a broader engineering walkthrough, this short explainer is worth a look:
What doesn’t work
Several rollout habits consistently create trouble:
- Shared handlers with hidden branching everywhere: The code becomes impossible to reason about and accidental drift becomes normal.
- One dashboard for all versions: You lose the ability to detect version-specific instability.
- No explicit support cap: Legacy versions linger because nobody owns removal.
- Migration by announcement only: Publishing docs without active support leaves partner teams stranded.
Zero downtime is not a launch tactic. It’s a sustained operating mode until the old contract is gone.
Driving Client Adoption and Sunsetting Old Versions
Shipping v2 isn’t the finish line. The migration only ends when v1 is retired and nobody important is surprised.
Technical teams often lose momentum. They build the new contract, stand it up correctly, and then assume clients will move because the new version is available. That doesn’t happen at scale. Clients move when the path is clear, the support is real, the incentives make sense, and the old version has a credible end.
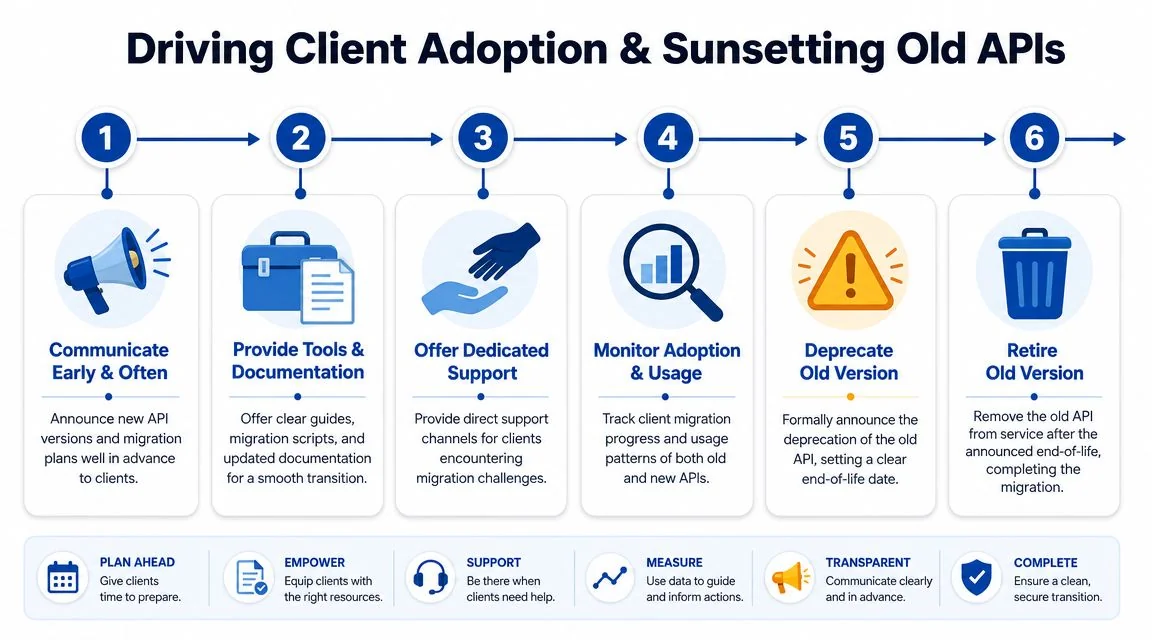
A workable client migration motion
The best migrations follow a simple pattern. Announce early. Document aggressively. Support the laggards. Monitor actual usage. Then enforce the sunset.
A communication plan doesn’t need marketing polish. It needs precision:
| Stage | What clients need |
|---|---|
| Initial announcement | What is changing, who is affected, and why the old contract will not remain indefinite |
| Documentation release | Side-by-side request and response examples, known behavior differences, migration steps |
| Active support window | Office hours, dedicated support channels, escalation path for blockers |
| Deprecation notice | Clear statement that the old version is entering retirement and what happens next |
| Final retirement notice | Firm removal date, final reminders, operational contacts for last-mile issues |
Target the clients who haven’t moved
Generic reminders don’t finish migrations. Targeted outreach does.
Use your API analytics and gateway logs to identify which consumers are still using deprecated endpoints, which operations they depend on, and whether their usage is dropping or flat. Then split outreach by consumer type:
- Internal teams: Enforce backlog commitments with engineering management. Internal consumers often delay because they assume the platform team will keep old behavior alive.
- External customers: Give practical migration guides and named support contacts.
- Partners with contract sensitivity: Coordinate timelines explicitly. These clients often need review cycles outside engineering.
New features motivate early adopters. Sunset dates motivate everyone else.
That doesn’t mean coercion should be the first tool. It means the migration plan needs both pull and push. Exclusive capabilities on the new version create pull. A firm deprecation path creates push.
When brownouts are justified
Planned brownouts are useful late in the process. They create a controlled interruption on the old version for short periods so consumers discover they still depend on it before the final cutoff. Used carefully, brownouts flush out the last hidden integrations.
They only work when three conditions are true:
- Clients have already received repeated communication.
- Monitoring shows usage is low enough that a short interruption is manageable.
- Your support team is staffed and ready during the event.
Brownouts are not a substitute for a migration program. They are a forcing function at the end of one.
The teams that finish API migrations well act like service owners, not just software publishers. They follow up, help consumers move, and retire old behavior with discipline instead of apology.
Why Migrations Fail and How to De-Risk Your Project
Most failed API versioning strategy migration efforts collapse in predictable ways.
The first failure mode is the unnecessary migration. The team created a new version when additive change would have preserved compatibility. They bought themselves permanent operational overhead for a problem that didn’t require a fork.
The second is the build-it-and-they-will-come fallacy. Engineering ships the new version and assumes clients will migrate on their own. They won’t. Without active documentation, outreach, support, and usage tracking, adoption stalls.
The failure patterns to look for early
-
Zombie versions
No firm sunset policy exists, so legacy behavior remains “temporary” for years. Support, testing, and routing complexity keep growing. -
Silent breaks
A supported version changes accidentally because contract protections are weak. This makes strong contract testing for microservices and legacy modernization more than a QA tactic; it becomes a governance control. -
Version sprawl
Teams keep adding exceptions for one more client or one more partner until nobody can state which versions are officially supported.
The expensive part of API modernization isn’t releasing a new version. It’s carrying old promises longer than planned.
Immediate next steps
If you’re about to start a migration, do these three things before building v2:
- Run a versioning gate. Prove the change requires a new version rather than additive evolution.
- Write the coexistence plan. Define test scope, routing model, monitoring boundaries, support ownership, and sunset policy.
- Name the consumer migration owner. Someone must own client adoption with the same seriousness the platform team owns uptime.
A credible migration plan is operational, not aspirational. If the retirement policy is vague, the support model is informal, or contract testing is missing, the project isn’t ready.
If you’re evaluating a broader modernization program and need hard-nosed guidance on migration risk, implementation trade-offs, and when not to buy external help, Modernization Intel is built for that kind of decision.