
Change Management for IT Modernization: A CTO's Playbook
Most modernization failures aren’t technical failures. They’re executive mistakes dressed up as architecture work.
Leaders approve a cloud migration, a mainframe exit, a data platform rebuild, or a DevOps toolchain overhaul as if the hard part is code conversion. It isn’t. The hard part is getting delivery teams, operations, security, finance, and business owners to change how they work at the same pace the platform changes underneath them. When that doesn’t happen, the program slips, rework piles up, and the business pays twice. Once for the migration itself, and again for the disruption.
That’s why change management for IT modernization belongs in the same risk register as security, resiliency, and data integrity. If you can’t explain who must change, what behavior must change, how readiness will be measured, and what happens if adoption stalls, you don’t have a modernization plan. You have a technical proposal.
Why Modernization Fails on People Not Code
70% of change initiatives fail due to ineffective change management, projects with excellent change management achieve 88% success rates, projects with poor practices achieve 13% success rates, and employee resistance accounts for 39% of failures. For a CTO, that changes the framing immediately. The primary risk in modernization isn’t just the target architecture. It’s whether the organization can absorb the operating model required to run it.

A team can produce clean Terraform, pass security review, and still fail because release managers cling to old CAB routines, platform teams hoard access, or business owners refuse to retire parallel processes. None of those issues show up in a migration diagram. All of them show up in missed milestones.
The financial risk is operational, not sentimental
Treating people issues as “soft” creates bad capital allocation. Leadership funds code remediation, integration work, and cloud landing zones, then underfunds training, role redesign, communications, and transition governance. The result is predictable. The technology goes live, but the organization keeps behaving like the legacy estate is still in charge.
That drives costs in familiar ways:
- Idle delivery capacity: Engineers wait for approvals, clarifications, and decisions that should have been resolved before cutover.
- Dual-running overhead: Teams keep the old and new ways of working alive because no one forced an operational switch.
- Rework: Developers rebuild workflows to match old habits instead of the target operating model.
- Avoidable instability: Support teams inherit systems they weren’t trained to run.
Practical rule: If your business case counts infrastructure savings but ignores adoption risk, the business case is incomplete.
A useful way to explain this to the board is simple. Legacy modernization changes authority, workflows, incident response, release ownership, and skill requirements. That’s not HR theater. That’s production risk.
What serious teams do differently
Strong programs define change management for IT modernization as a control system. They map who loses control, who gains new responsibility, and where resistance will surface first. They also tie every migration wave to operational readiness, not just technical readiness.
If your organization is still treating change as a communications workstream, it’s behind. The better model is to treat it like architecture governance. It needs named owners, entry criteria, exit criteria, and escalation paths.
A good starting point is to assess whether the proposed modernization path matches the organization’s actual capacity to adopt it. That means looking beyond the platform and into the surrounding operating model. In this scenario, a broader view of modernization of technology becomes useful. The technical path and the organizational path have to line up, or neither will hold.
The Governance Framework for Change
Governance breaks when modernization decisions are made in one room and operational consequences land in another. The fix isn’t more steering meetings. It’s a model that separates strategic authority, technical approval, execution ownership, and adoption accountability.
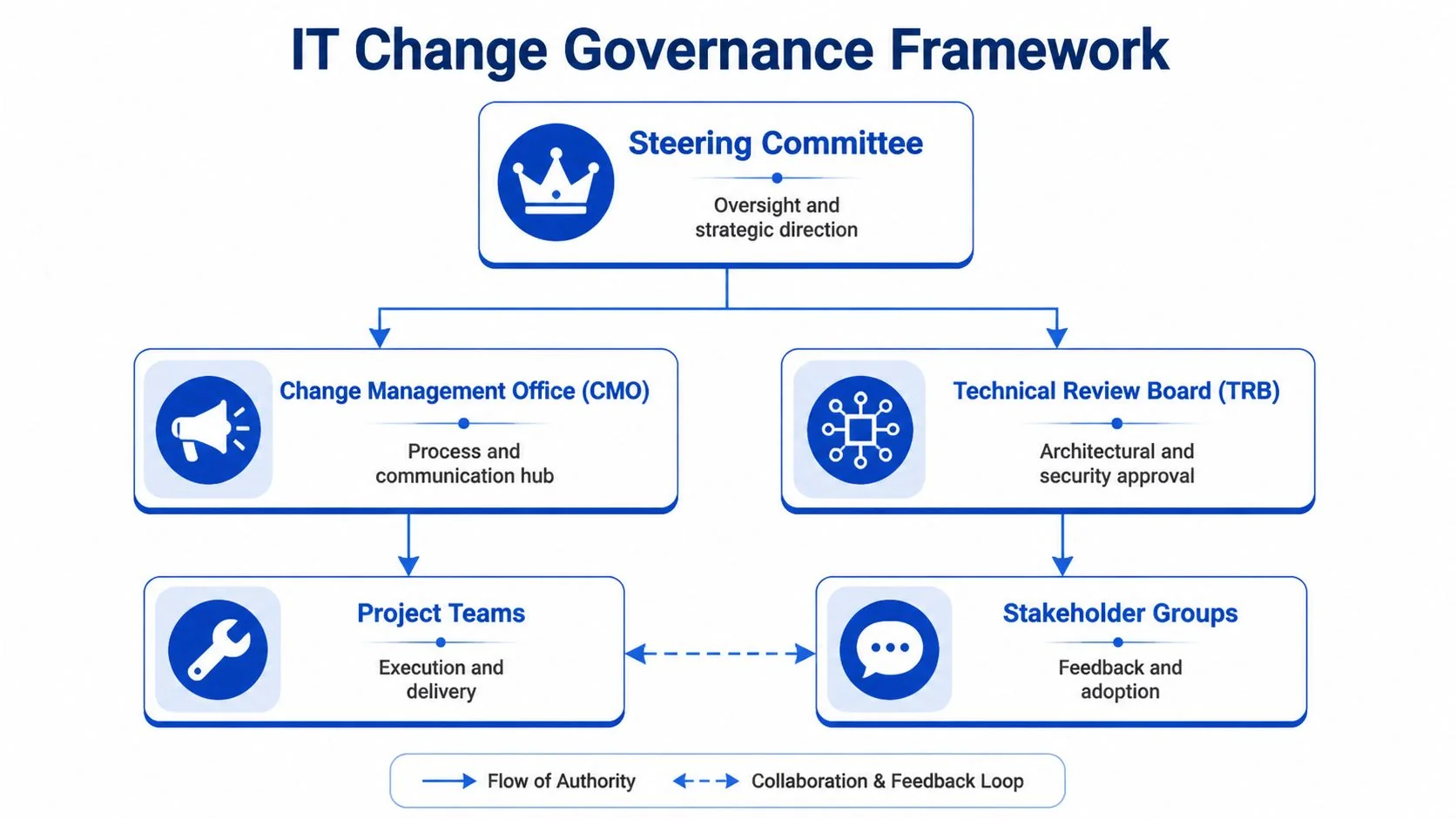
The structure below works because it forces the human side of modernization into the same decision flow as architecture and delivery.
Set up four layers of authority
-
Steering committee
This group decides funding, sequencing, and escalation. It shouldn’t debate training formats or tool configuration. Its job is to resolve cross-functional conflicts fast. -
Change management office
Call it a CMO, transformation office, or delivery enablement function. The name matters less than the mandate. This team owns readiness tracking, stakeholder mapping, communications, and cutover impact planning. -
Technical review board
The TRB approves architecture, security, data migration patterns, and operational controls. It should also block releases when the adoption prerequisites aren’t met. -
Project teams and stakeholder groups
These teams execute the migration, validate process changes, test runbooks, and surface resistance before it shows up as production friction.
A lightweight visual helps teams understand that split of authority before the program starts.
After that, give leaders a common baseline. For teams that need a concise primer, these essential change management insights for businesses are useful because they frame change as a managed discipline instead of a vague cultural exercise.
Run a stakeholder audit like an engineering dependency review
Don’t build the stakeholder map from the org chart. Build it from control points. Ask:
- Who approves production changes today
- Who owns the current release process
- Which teams carry undocumented legacy knowledge
- Who gets measured on stability and therefore has incentives to resist risk
- Which business leaders must change daily workflows after cutover
That gives you a practical influence map, not a decorative one.
The people most likely to delay a migration often aren’t the loudest opponents. They’re the managers who quietly keep legacy workflows alive.
Put readiness gates into the delivery plan
The governance model needs decision gates that stop a wave when the organization isn’t ready to absorb it. Typical gates include:
- Before build starts: named business owner, named operations owner, named training owner
- Before pilot release: updated runbooks, support model agreed, affected teams briefed
- Before cutover: role-based training completed, support escalation path tested, legacy fallback decision approved
- After go-live: adoption review, process compliance review, backlog of workarounds assigned
The video below is a useful reference point for leaders trying to operationalize those controls.
Build a RACI that reflects modernization reality
A generic RACI fails because modernization changes accountability. Use a task-specific model instead.
| Decision or task | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Approve target architecture | TRB | CTO or architecture lead | Security, platform, app owners | Steering committee |
| Define migration wave scope | Program manager, app leads | Steering committee | Finance, ops, business owners | Affected teams |
| Train engineers on new toolchain | Engineering managers, enablement leads | VP Engineering | Platform team, security | Delivery teams |
| Communicate cutover impact | Change office, product owners | Program sponsor | Service desk, operations | End users, support teams |
| Sign off go-live readiness | Project lead, ops lead | Executive sponsor | TRB, business owner | Steering committee |
If accountability is fuzzy, resistance hides inside “alignment.” Governance fixes that by making decisions explicit.
Designing a High-Impact Communication and Training Plan
In IT modernization, 79% of projects fail, and a step-by-step approach that integrates the ADKAR model with technical phases is critical. The same source ties strong change capability to a +6% revenue uplift. Most organizations know they need communication and training. They fail because they treat both as generic broadcasts delivered too late.
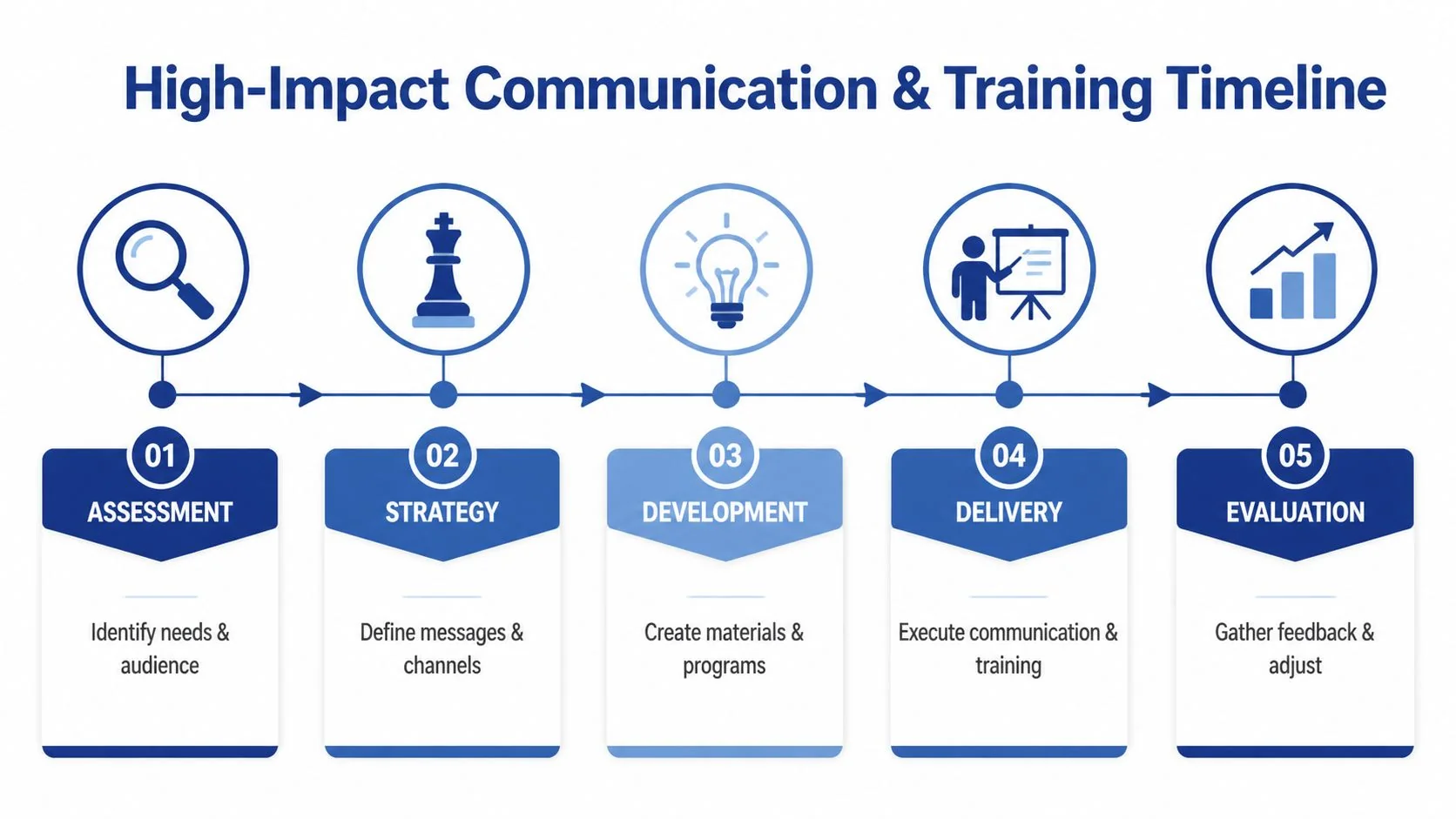
The practical way to use ADKAR in software modernization is to tie each element to a technical transition point.
Awareness and desire need technical specificity
Engineers don’t buy into a new platform because leadership says it supports “digital transformation.” They buy in when they understand what pain goes away and what control they keep.
For example:
- A mainframe team needs clarity on what business logic is preserved, what gets rewritten, and who validates equivalence.
- A platform engineering team needs to know whether they inherit support for the new runtime on day one.
- A security team needs to know what controls move left and which controls remain gated.
Desire follows when people can see a better working model, not just a different stack. Pilot migrations help because they make benefits visible in a bounded environment. If deployment friction drops, if testing becomes more reliable, or if incident diagnosis improves, teams start backing the change for operational reasons.
Knowledge and ability need role-based delivery
Most training plans collapse here. They send everyone to the same deck, then call attendance “enablement.”
Use role-based paths instead:
- COBOL or legacy application developers: code reading sessions on translated logic, test harness walkthroughs, paired work with target-stack engineers
- Platform engineers: runtime operations, observability setup, deployment rollback drills
- Support and SRE teams: new alert patterns, incident playbooks, service dependency maps
- Product and business operations: workflow changes, reporting differences, temporary cutover constraints
Training works when it mirrors production work. If people can’t rehearse their real tasks before go-live, they aren’t trained.
A strong plan also includes sandboxes, paired programming, office hours, and runbook simulations. Brown-bag sessions are useful for awareness. They are not enough for ability.
Reinforcement is what keeps the old system from winning
Teams revert fast under pressure. If incidents spike or deadlines tighten, people fall back to the old workflow unless leadership reinforces the new one through process and accountability.
Use a simple reinforcement checklist after each release:
| Reinforcement area | What to verify |
|---|---|
| Process adherence | Are teams using the new deployment and support workflow |
| Tool adoption | Are engineers actually working in the new CI/CD and observability path |
| Escalation behavior | Are incidents routed through the new ownership model |
| Workarounds | Which legacy shortcuts are still being tolerated |
A communication plan should also change tone over time. Early messages should explain why the modernization exists. Mid-program updates should focus on role impact and upcoming decisions. Late-stage messages should be brutally specific about cutover expectations, support coverage, and what stops being acceptable after go-live.
That sequence is what makes change management for IT modernization operational rather than ceremonial.
Common Failure Modes and Their Mitigations
The failures that derail modernization are rarely surprising after the fact. They’re visible early, but teams misread them as personality issues, temporary friction, or “normal resistance.” That’s a mistake. These are failure modes. They need the same discipline you’d apply to capacity bottlenecks or data corruption risk.
One of the most overlooked examples is the layer between executive sponsorship and frontline engineering. Standard change management advice often misses that middle managers, fearing role obsolescence, undermine 55% of IT modernization initiatives, and the same cited source says success is 2x higher when those managers are incentivized via equity stakes in modernization ROI. If your program assumes those managers will naturally align, you’re trusting the wrong incentive structure.
What the warning signs look like
Middle-manager sabotage rarely looks dramatic. It shows up as endless requests for more validation, insistence on duplicate reporting, refusal to retire old approval flows, and selective escalation of every defect in the new environment while legacy failures are treated as routine.
Another pattern is legacy expert hoarding. A few senior engineers become gatekeepers for critical knowledge. Leadership praises them for keeping things running, but the behavior blocks documentation, cross-training, and decomposing the system into manageable migration waves.
When a modernization depends on a handful of heroes, the organization is protecting the legacy estate, not replacing it.
Modernization change failure modes
| Failure Mode | Early Symptom | Mitigation Strategy |
|---|---|---|
| Middle-manager blockage | New approvals appear, pilot scope keeps shrinking, every change is reframed as operational risk | Tie manager incentives to modernization outcomes, make approval authority explicit, escalate duplicate governance fast |
| Legacy expert hoarding | Critical knowledge stays in chat threads and private notes, not in runbooks or repos | Require documentation as a delivery artifact, pair legacy experts with target-state owners, make handoff visible in sprint reviews |
| Toolchain theater | Teams attend training but continue shipping through old paths | Decommission legacy workflows on a schedule, measure actual usage of the new path, assign one owner for cutover enforcement |
| Perfectionist paralysis | Teams delay release waiting for edge-case certainty while business value sits idle | Set decision thresholds in advance, use pilots to validate critical assumptions, separate must-fix defects from post-go-live backlog |
| Executive overconfidence | Leadership assumes a technical milestone equals adoption | Add operational readiness reviews, include support and business teams in sign-off, publish unresolved people risks alongside technical risks |
| Change fatigue | Teams disengage, skip optional sessions, or stop reading updates | Sequence changes by business capacity, show visible wins, pause nonessential disruption when the organization is overloaded |
Mitigation has to change incentives, not just messaging
A lot of remediation advice is too polite. You won’t solve incentive misalignment with town halls. If a manager’s status depends on preserving a legacy approval process, no slide deck will fix that. Change the metric, change the authority model, or change the manager.
The same applies to legacy talent. If your most experienced engineers are treated as irreplaceable, they’ll keep acting irreplaceable. The answer isn’t to push them out. It’s to make knowledge transfer and target-state readiness part of their job, and part of how performance is judged.
This is why pre-mortems matter. Before each migration wave, ask which roles lose control, which teams inherit risk, and what behavior would subtly impede the release. Then design the mitigation into governance, not just into communications.
Vetting Partners and Measuring Real Success
A partner can be technically excellent and still make your modernization harder. That happens when the SOW rewards code delivery but ignores adoption, operating model transition, and handoff quality.
That risk is bigger than most buyers admit. Only 32% of change initiatives fully succeed, Prosci’s research shows excellent change management makes projects 8 times more likely to meet objectives, and without strong change practices even specialized firms risk contributing to a 72% transformation failure rate. If you don’t evaluate partner capability on the people side, you’re selecting for presentation quality, not execution quality.
What to ask before signing
Don’t ask whether the partner “does change management.” Every firm says yes. Ask questions that expose method and accountability.
Use questions like these:
- Show the readiness criteria you use before a migration wave goes live
- Describe how you map impacted roles for platform, security, support, and business operations
- What deliverables do you produce for training, cutover communication, and runbook transition
- Who owns adoption after go-live
- Tell me where your last modernization program stalled because of organizational resistance and what you changed
Their answers should be specific. If they jump back to tooling, architecture, or generic PMO language, they probably don’t have a mature change discipline.
A buyer-side review process helps here. This vendor due diligence checklist is a useful way to force evidence, compare claims, and make sure change capability is part of partner selection rather than an afterthought.
Put change metrics into the contract
If you want a partner to care about adoption, write it into the statement of work. That doesn’t mean inventing vanity metrics. It means defining observable outcomes tied to the transition.
Good SOW language usually includes:
| Contract area | What to include |
|---|---|
| Readiness deliverables | Stakeholder map, communication plan, training plan, support transition plan |
| Go-live criteria | Named approvers from engineering, operations, business, and support |
| Knowledge transfer | Required documentation, paired sessions, runbook walkthroughs |
| Hypercare | Incident triage ownership, escalation paths, handoff checkpoints |
| Exit conditions | Evidence that internal teams can operate, support, and extend the modernized system |
Measure business adoption, not just system health
Uptime matters. Build success matters. Security posture matters. None of those alone tell you whether the modernization worked.
Track outcomes such as:
- Operational adoption: Are releases, incidents, and support requests flowing through the new model
- Team readiness: Can internal engineers change and support the system without leaning on the partner
- Workflow retirement: Have old approvals, old scripts, and old reporting paths been shut down
- Time to effective ownership: How quickly can the receiving teams operate independently
If you also need to backfill delivery capacity during the transition, external staffing can help, but keep the objective narrow. If you hire full-stack developers, do it to accelerate bounded delivery work while keeping ownership of architecture, runbooks, and organizational adoption inside your leadership team. You can outsource coding capacity. You can’t outsource accountability for change.
The Final Go/No-Go Decision
Some modernization programs shouldn’t start yet. Others shouldn’t start at all.
That sounds obvious, but most governance models still assume the only real decision is which platform, which pattern, and which partner. The harder question is whether the organization is ready to absorb the change without destroying the expected value. That gap matters because one cited analysis argues that 70% of software modernization projects fail due to people-related issues, and change management contributes to 40% of overruns averaging $2.5M per project.
Red flags that should stop the program
Postpone the effort if several of these are true:
- No credible business owner exists for the process that will change after migration.
- Operations and support teams weren’t involved in shaping the target-state model.
- Leadership can’t name the roles most likely to resist the change.
- Training is scheduled near cutover instead of built into the migration plan.
- The business case depends on immediate adoption but no one is accountable for enforcing workflow retirement.
- Critical managers are visibly misaligned and still control approvals or staffing.
- Success is defined only in technical terms such as delivery of code, completion of migration, or infrastructure shutdown.
Don’t approve a modernization because the legacy platform is frustrating. Approve it when the target-state operating model is governable.
A defensible go decision
A go decision is solid when leadership can answer five questions clearly:
- What business behavior changes on day one
- Who owns the change by role, not by committee
- What will be retired, forbidden, or no longer supported
- How will readiness be checked before each wave
- What evidence will prove the organization can run the new estate without dependency drift
If those answers aren’t available, the right move is delay. That isn’t indecision. It’s loss prevention.
For technical leaders making high-stakes calls, that’s the core truth about change management for IT modernization. The problem isn’t convincing people to be positive. The problem is designing a transition that people can execute under production pressure.
If you’re evaluating a modernization path and want a less biased view of partner fit, failure patterns, and when not to proceed, Modernization Intel at Software Modernization Intelligence publishes research to help technical leaders make defensible decisions.