
A CTO's Guide to Event-Driven Architecture Modernization
Event-driven architecture has already crossed from early adoption into mainstream planning. A large share of companies have implemented it, and another meaningful share intend to do so soon, as noted in earlier market reporting. That adoption signal matters less than many CTOs assume.
What matters is whether the business can absorb the operating cost and failure profile that comes with asynchronous systems.
EDA modernization is often sold as a clean technical upgrade. In practice, it is a risk transfer. Complexity moves out of the monolith and into event contracts, replay handling, ordering guarantees, schema versioning, and cross-service forensics. Firms that budget only for broker rollout and application refactoring usually miss the expensive part. They discover later that observability, governance, and reliability engineering consume a large share of the program.
That is why the right evaluation standard is financial, not architectural. A modernization program that increases deployment speed but also raises incident frequency, audit exposure, or reconciliation labor can destroy value even if throughput improves. The common failure pattern is predictable: teams publish events before ownership is clear, skip idempotency because deadlines are tight, and postpone lineage and tracing until production issues force the spend.
The result is not theoretical. It shows up as duplicate transactions, broken downstream automations, delayed revenue recognition, and long incident investigations spread across multiple teams.
CTOs should treat EDA modernization as a portfolio bet with asymmetric downside. The upside is real, but only if the organization can price the hidden controls upfront and prove that the business event flows are important enough to justify them.
The EDA Modernization Paradox
Analysts do not need another forecast to see the pattern. EDA adoption has moved from edge case to default shortlist in modernization programs, yet a large share of implementations still underperform because the buying decision is made on architecture optics rather than operating economics.
That gap creates the paradox. The same design choices that improve decoupling and reaction speed also increase the number of failure states the business must detect, explain, and fund. A monolith fails loudly. An event-driven system often fails subtly, then sends the invoice later through reconciliation work, customer-facing defects, and elongated incident response.
Adoption is mature enough. Operating discipline often is not.
The optimistic case for EDA is already well understood, and noted earlier in this article. Real-time workflows, asynchronous buffering, and independent service release cycles are legitimate advantages. They are also the easy part of the pitch.
The hard part is execution under production conditions. Events arrive out of order. Consumers process the same message twice. Schemas drift while teams assume backward compatibility. Replay fixes one downstream error and creates another because business rules changed after the original event was published. None of this means EDA is flawed. It means the failure surface shifts from application code in one place to system behavior across many places.
EDA does not reduce complexity. It changes where complexity lives, who owns it, and how expensive it is to recover when it breaks.
That cost shift is why many modernization programs look successful during migration and disappointing six months later. Initial milestones measure broker deployment, service extraction, and throughput gains. The actual business exposure sits elsewhere: contract breakage, audit gaps, duplicate side effects, weak lineage, and incident triage spread across platform, application, and data teams.
Many leadership teams still ask the wrong first question
“Will EDA help us scale?” is not a decision standard. It is a feature check.
The question a CTO should force early is narrower and more financially useful: which business flows are valuable enough, time-sensitive enough, or failure-prone enough to justify the control overhead of asynchronous systems? If the answer is vague, the program is usually architecture-led rather than economics-led.
A defensible decision rests on three tests:
- Contract discipline: teams version schemas deliberately, assign clear ownership, and treat event definitions as governed interfaces
- Operational maturity: the organization can trace a business transaction across async hops, retries, dead-letter queues, and replay paths
- Domain boundary quality: service cuts align to stable business capabilities rather than to org charts or sprint-level convenience
Miss one of those, and the program absorbs the worst trade available. Higher coordination cost, weaker debuggability, and new forms of coupling hidden behind a broker.
That is the paradox. EDA often becomes attractive at exactly the point when a company is least prepared to run it well.
Business and Technical Drivers Beyond Scalability
If your only business case is “we need scale,” your business case is weak.
Most monoliths can scale further than teams assume. The sharper justification for event-driven architecture modernization is that the business needs real-time reaction, team autonomy, or failure isolation that synchronous, tightly coupled systems no longer support.
Real-time decisions, not batch-era latency
The strongest driver is decision speed.
Payment flows, customer notifications, fraud signals, inventory movement, and operational alerts all benefit when systems publish events as facts and downstream services react immediately. That’s different from polling databases, waiting on scheduled jobs, or forcing every dependency through a blocking API chain.
Teams often describe this as a scalability problem. It usually isn’t. It’s a latency-of-decision problem. The architecture matters because the business can’t wait for batch windows or tightly coupled request chains to complete before acting.
Team independence is a financial driver
The second driver is delivery friction.
Monoliths don’t only slow runtime behavior. They slow engineering organizations. Every release becomes a coordination exercise because too many teams depend on the same codebase, the same deployment pipeline, or the same database contracts. Event-driven systems can break that lockstep if teams publish stable events and let consumers evolve independently.
That matters more than architectural elegance. It changes how quickly product teams can ship changes without negotiating every release against unrelated services.
Practical rule: If EDA doesn’t improve release independence or time-sensitive business reactions, the added complexity is hard to justify.
Spike resilience matters when revenue flows are bursty
The third driver is operational continuity under uneven demand.
Some businesses don’t fail under average load. They fail at peak moments, during payment surges, customer campaigns, seasonal spikes, or external partner bursts. EDA gives you buffering and asynchronous processing, which is often the difference between degraded performance and broken business flows.
You can see that logic in how large-scale platforms use event systems to absorb volume and route work across distributed services. The value isn’t abstract “cloud native” positioning. The value is that one downstream slowdown doesn’t have to freeze the entire transaction path.
A simple business test
Use this before approving an EDA program:
| Driver | Weak justification | Strong justification |
|---|---|---|
| Decision speed | Batch is acceptable | The business needs immediate reaction to events |
| Team autonomy | One team owns most change | Multiple teams need independent delivery |
| Spike handling | Traffic is predictable | Demand surges create operational risk |
| Integration model | Point-to-point works | Too many dependencies are brittle and slow |
If you only check one box, pause. If you clearly check three, EDA is becoming defensible.
Choosing Your EDA Migration Pattern
Migration pattern choice decides whether modernization compounds value or compounds risk.
Most failed EDA programs don’t fail because brokers are bad or events are a bad idea. They fail because teams pick a migration pattern that doesn’t match the monolith’s shape, data dependencies, or the organization’s tolerance for ambiguity.
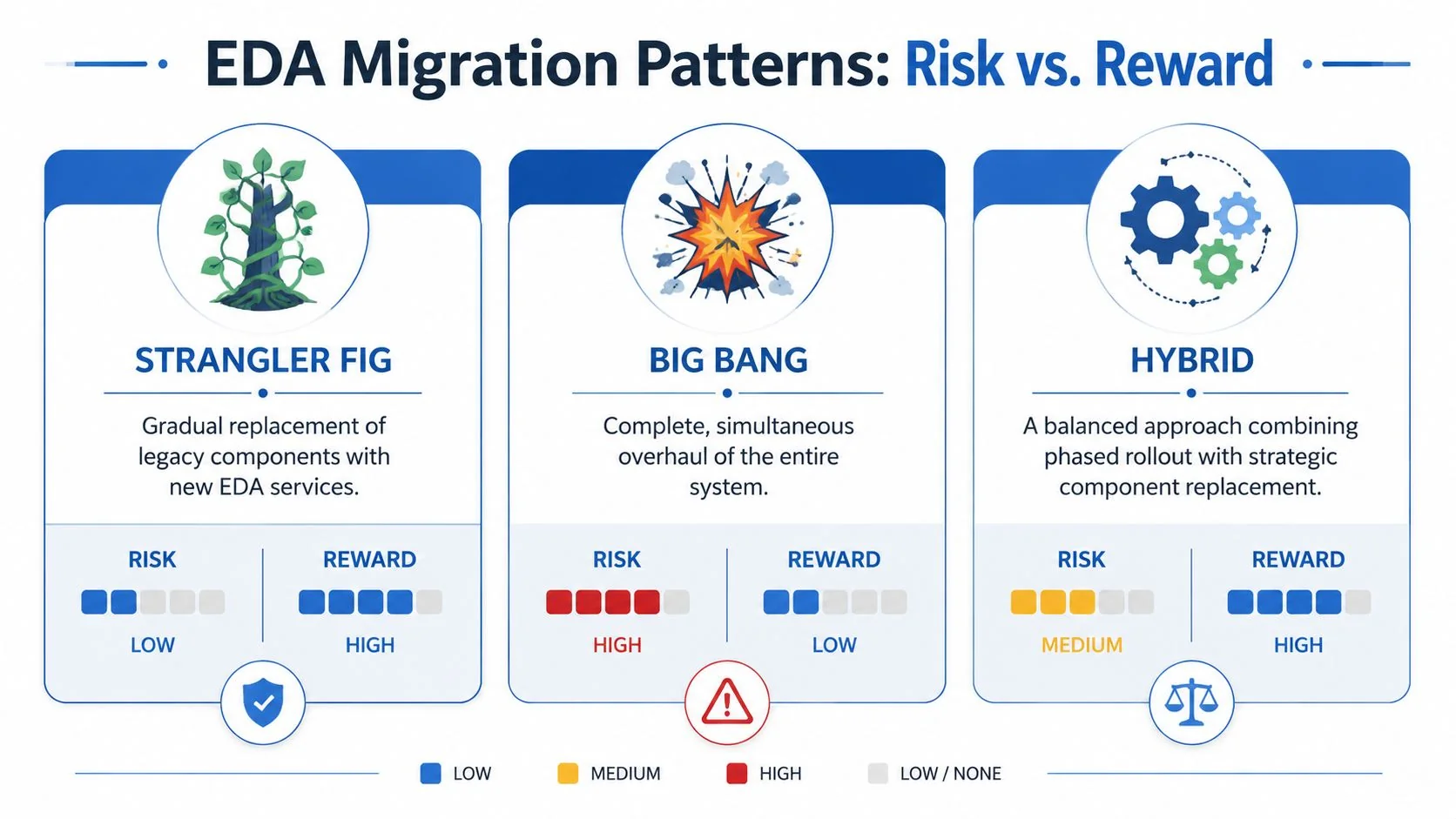
Strangler Fig works when boundaries are real
The Strangler Fig pattern is still the most defensible choice for complex legacy systems. You extract one business capability at a time, route specific behavior into a new service, and let the old system keep running while the new edges expand.
This pattern only works if you can identify stable semantic boundaries. “Customer notifications” is a plausible boundary. “Shared business logic used by six teams and three databases” is not.
Good candidates for extraction usually have these traits:
- Clear event triggers: order placed, payment captured, user registered
- Low hidden coupling: fewer surprise writes into unrelated tables
- Observable outcomes: you can verify whether the new path behaved correctly
- Limited rollback blast radius: if it breaks, core revenue flow still survives
For teams trying to modernize legacy systems for startups, the same logic applies. Start with edges that create business advantages without forcing a full core rewrite.
Parallel Run is expensive but sometimes necessary
A Parallel Run pattern is the right move when the cost of being wrong is higher than the cost of temporary duplication. The legacy path and the new event-driven path both execute, and the team reconciles outputs until confidence is high enough to cut over.
That sounds safer than it is. The hard part isn’t standing up two paths. The hard part is the reconciliation loop.
You need explicit answers to these questions:
- Which system is authoritative when outputs diverge?
- How will teams detect silent mismatches, not just hard failures?
- What business process decides when confidence is sufficient for cutover?
If you can’t answer those, parallel run becomes a prolonged state of uncertainty that burns budget and engineering attention.
A useful framing for migration trade-offs appears in this guide to migration patterns. The pattern isn’t just a technical tactic. It sets the governance model for the entire transformation.
Here’s a concise visual explainer before going further:
Big Bang rewrite is usually executive optimism dressed as strategy
The Big Bang approach appeals to leaders who want a clean break. In practice, it forces teams to re-create behavior, untangle hidden dependencies, redesign contracts, and cut over everything at once.
That’s not bold. It’s structurally fragile.
A monolith with years of undocumented business rules rarely tolerates simultaneous replacement. Teams discover edge cases late, test coverage proves weaker than expected, and rollback becomes politically or technically impossible. The result is often a half-finished target architecture and a production risk nobody wants to own.
Don’t choose Big Bang because the old system is ugly. Choose incremental patterns because the old system is opaque.
A direct decision guide
| Pattern | Best fit | Main risk | CTO verdict |
|---|---|---|---|
| Strangler Fig | Monolith has extractable domains | Teams misidentify boundaries | Default choice for most enterprises |
| Parallel Run | Business can’t tolerate wrong output | Reconciliation becomes a second platform | Use selectively for critical flows |
| Big Bang | Rare greenfield-like replacement conditions | Cutover and rollback risk | Usually reject |
EDA Modernization Failure Modes and Financial Impact
Most EDA modernization programs do not fail at the broker. They fail in the contract layer, the replay model, and the operational controls that finance teams rarely see in the initial business case.
That distinction matters because the cost profile is asymmetric. A bad infrastructure choice is expensive. A bad event model can trigger billing errors, inventory distortion, customer-facing reversals, and audit exposure across multiple systems before anyone can isolate the source. The architecture looked distributed. The liability became centralized.
Schema drift is the first financial landmine
Schema evolution is where many EDA programs start accumulating hidden losses. Confluent notes in its schema evolution guidance that data and schema issues are a major source of downstream breakage in event systems, and its documentation on compatibility and schema management explains why uncontrolled producer changes routinely break consumers at runtime: https://docs.confluent.io/platform/current/schema-registry/fundamentals/schema-evolution.html
The practical implication is simple. Once an event is consumed outside the producing service, the payload stops being an internal implementation detail. It becomes an external contract with an operating cost.
Teams that miss this usually underfund governance. They budget for broker rollout, service extraction, and developer capacity, then treat schema policy as documentation work. That is a category error. A weak contract model creates rework, rollback delays, emergency patches, and manual reconciliation. If your modernization plan lacks explicit funding for schema ownership, compatibility policy, and deprecation rules, the plan is understating total cost.
A useful way to frame it is this: the event contract is part of your strategic software architecture blueprint, not a byproduct of implementation.
Idempotency failures create direct P&L damage
Duplicate delivery is normal in systems designed for reliability. Duplicate side effects are not.
At-least-once delivery shifts the burden to consumer design. If a consumer cannot process the same event twice without creating a second business action, retries stop being a resilience feature and become a revenue leakage mechanism. The classic examples are obvious. Double charges, duplicate emails, repeated shipments. The less obvious ones are often more expensive. Duplicate credit issuance, duplicate entitlement activation, or duplicate ledger updates can sit undetected until finance closes the month.
Ordering failures are similar. Individual services can report success while the business process is already corrupted. A refund event applied before settlement. A cancellation processed before fulfillment confirmation. A customer state transition accepted in one bounded context and rejected in another. Local health checks stay green. End-to-end truth is broken.
The dangerous version of EDA failure is not an outage. It is a silent accounting error that propagates faster than your reconciliation process.
Observability gaps turn small incidents into long, expensive ones
Asynchronous systems fail sideways. Without correlation IDs, trace propagation, and replay visibility, incident response degrades into timeline reconstruction by log scraping.
That has a measurable cost even when no customer is directly harmed. Senior engineers get pulled into cross-team war rooms. Product and operations teams lose confidence in event-driven flows. Release velocity slows because every new consumer is treated as a risk multiplier. This is one reason some EDA programs stall after the first few domains. The architecture is technically live but economically mistrusted.
Top EDA Modernization Failure Modes and Likely Cost Exposure
| Failure Mode | Technical Root Cause | Business Impact | Prevention Strategy |
|---|---|---|---|
| Schema drift between producers and consumers | No schema registry, weak compatibility rules, ungoverned payload changes | Consumer runtime failures, broken integrations, manual reconciliation, release delays | Enforce schema registry, compatibility checks, version policy, and owner accountability |
| Duplicate event processing | Retries without idempotent consumer logic | Double execution of billable or regulated actions, ledger inconsistencies, customer remediation cost | Use idempotency keys, dedupe stores, and consumer logic safe for reprocessing |
| Event ordering failures | Workflows assume sequence that topology or broker does not guarantee | Invalid state transitions, fulfillment errors, refund and settlement mismatches | Identify ordering-sensitive flows early and redesign around explicit sequencing or compensating logic |
| Opaque asynchronous failures | No end-to-end tracing, weak correlation model, poor replay visibility | Long incident resolution cycles, high engineering interruption cost, lower release confidence | Instrument events with correlation IDs and trace across producer, broker, and consumer |
| Uncontained poison messages | No dead letter strategy, weak exception isolation, no replay runbook | Queue backlogs, repeated failures, operational escalation, delayed downstream processing | Route bad events to DLQs, define ownership, and build triage and replay procedures |
The remediation sequence that works
Start with contract governance. Define event naming, versioning, compatibility, validation, and deprecation rules before large-scale service extraction.
Then design for replay. Any consumer that cannot safely reprocess an event is a latent financial defect.
Map ordering-sensitive flows explicitly. Do not rely on assumptions inherited from synchronous systems. Prove where sequence matters and where eventual consistency is acceptable.
Finally, operationalize failure handling before launch. Dead letter queues without ownership, replay controls, and on-call procedures are just delayed incidents with better branding.
Teams often describe these controls as added complexity. They are not optional complexity. They are the minimum cost of making asynchronous business processes financially defensible.
Comparing Core Architecture and Broker Options
Broker selection sets your cost structure before it sets your latency profile.
Teams often treat Kafka, EventBridge, Pub/Sub, and managed streaming platforms as interchangeable boxes on an architecture diagram. That is how modernization programs end up with the wrong staffing model, the wrong failure domain, and a broker bill that makes the original business case harder to defend. The fundamental decision is operational economics: how much control the business will use, what outage modes it can tolerate, and what platform overhead it is willing to fund year after year.
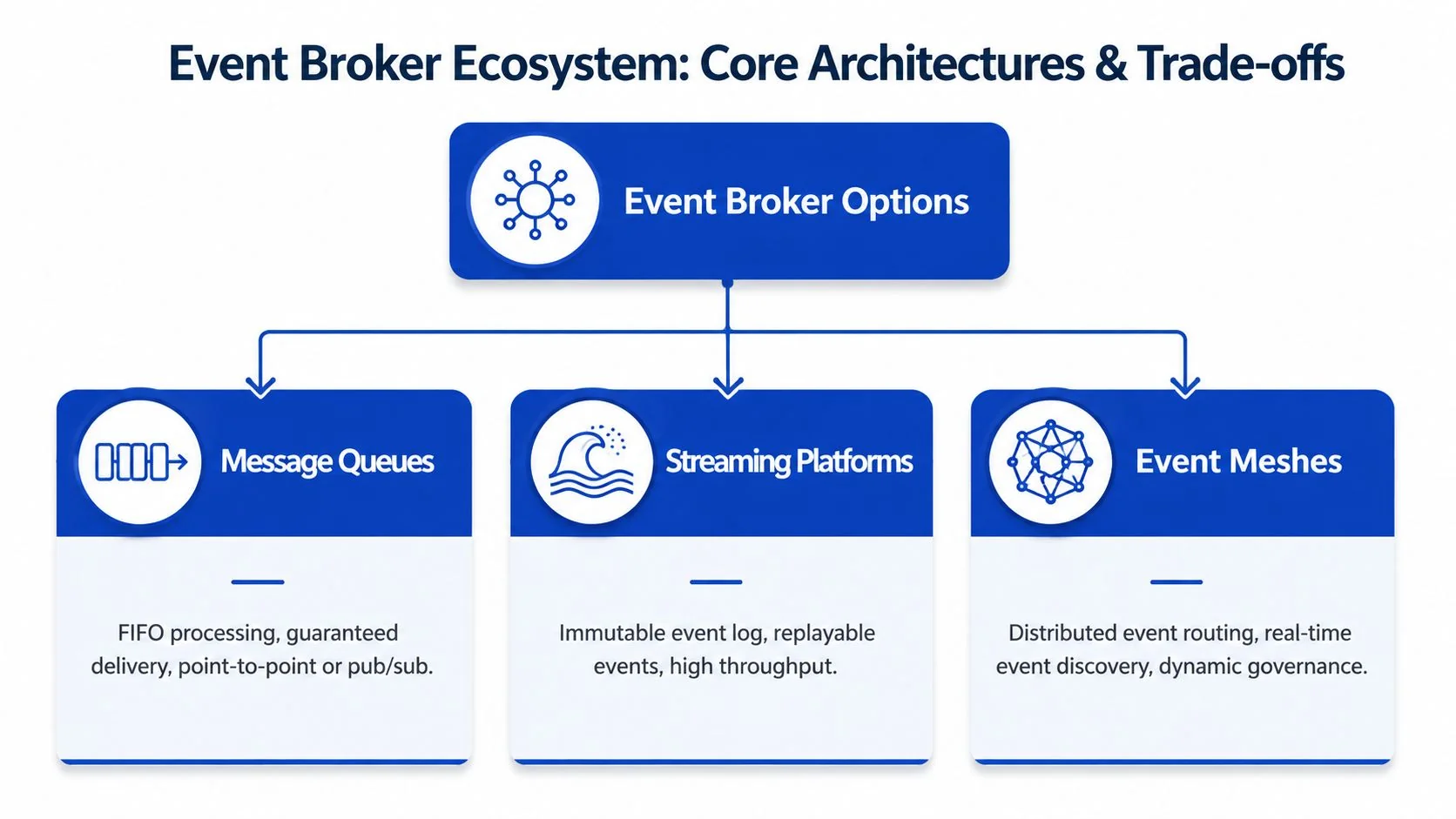
EventBridge is credible at production scale, within its operating model
Amazon’s published case study on Amazon Key gives a useful benchmark because it ties broker choice to measured outcomes, not vendor abstractions. In AWS’s Amazon Key EventBridge architecture case study, the team reports 80 ms p90 latency, 99.99% success rate, throughput of 2,000 events per second, and 14 million subscriber calls handled without adding new infrastructure.
The conclusion is narrower than many vendor pitches suggest. Managed event buses can support serious production workloads. They are a strong fit when routing, integration, and low operator burden matter more than fine-grained control over partitions, retention windows, and consumer lag behavior.
That distinction matters because many firms overbuy broker complexity. They adopt a streaming platform for workloads that are mostly integration events, then inherit operating costs that produce little business advantage.
Control has a price, and the bill usually arrives in headcount
Self-managed Apache Kafka offers the most control. It gives teams direct authority over partitioning strategy, retention policy, replay mechanics, and ecosystem tooling. That control is valuable if streaming is part of the product itself, analytics depends on durable event histories, or platform engineering is already a mature internal function.
It is expensive control.
Kafka is rarely a rational choice for organizations that want asynchronous integration but do not want to run a distributed data platform. In those environments, the technical upside is often real, but the financial downside is larger than expected. Staffing, upgrades, performance tuning, storage management, and cross-team support become recurring costs, not one-time migration tasks.
Managed options such as Amazon MSK and Confluent Cloud reduce some of that burden while preserving much of the streaming model. Native cloud buses such as Amazon EventBridge reduce it further, but they do so by imposing a more opinionated operating model and deeper cloud dependence.
For target-state planning, this strategic software architecture blueprint is useful because it frames the right question: what system can your organization operate reliably at 2 a.m., not what platform looks strongest in a benchmark slide.
A CTO-level comparison
| Option | Operational upside | Financial risk | Best fit |
|---|---|---|---|
| Self-managed Kafka | Full control over replay, retention, partitioning, and ecosystem choices | Highest labor cost, platform fragility if Kafka expertise is thin, longer recovery from broker-level incidents | Firms where event streams are core product infrastructure and platform engineering is already strong |
| Managed Kafka or Confluent Cloud | Keeps streaming depth while offloading part of the infrastructure burden | Subscription cost can rise fast, and teams still need real streaming expertise | Enterprises that need durable streams and replay control but want to cut broker administration |
| Native cloud event bus such as EventBridge | Lowest operator burden, fast integration with cloud services, shorter time to production | More constrained semantics, stronger cloud lock-in, less control over low-level broker behavior | Teams prioritizing delivery speed, integration, and lower ongoing operations cost |
Use a risk-based decision sequence
Evaluate broker options in this order:
- Is the business building a streaming capability or an event-routing capability? These are different investments with different staffing requirements.
- What is the cost of a missed event, delayed event, or duplicate event in dollars, customer impact, or compliance exposure? Broker features only matter relative to those failure costs.
- Does the team have proven operator depth for distributed messaging systems? Installing a broker is not the same as running one well under failure.
- How much replay, retention, and ordering control is required by the business process? Many teams specify for edge cases they never monetize.
- What observability model will this broker force you to build? Broker selection changes tracing, debugging, and governance costs. The operational implications are easier to see if you review observability requirements in modernized distributed systems.
A broker that exceeds your operational capacity is not a strategic asset. It is a recurring liability with better branding.
The Hidden Costs of Observability and Governance
Observability and governance are where many EDA business cases fail basic financial scrutiny.
The budget usually covers producers, consumers, and the broker. The expensive part shows up later. Incident triage across asynchronous flows, schema drift between teams, replay operations, DLQ ownership, and audit gaps all create recurring labor cost that rarely appears in the migration model. Those costs are not secondary. They determine whether the platform stays operable once event volume, team count, and business dependence increase.
Tracing failures become cost multipliers
Asynchronous systems remove the single request thread that made root-cause analysis straightforward. A customer-visible failure may start with one malformed event, surface three services later, and only appear after a retry window or timeout expires. Without correlation data, the investigation becomes a manual reconstruction exercise across logs, queues, and dashboards.
Infosys discusses observability, tracing, and operational control as prerequisites in cloud and application modernization guidance at https://www.infosys.com/services/cloud-cobalt/offerings/application-modernization-architecture.html. The broader point is clear even without overstating a single metric. If the team cannot trace one failed event from producer to broker to every consumer that touched it, mean time to resolution rises and recovery cost rises with it.
That has direct budget impact. Senior engineers get pulled into forensic work. Incident bridges run longer. Replay decisions become riskier because no one has a clean event history. In regulated environments, weak traceability also turns a technical outage into a reporting problem.
Governance is an operating control, not a paperwork layer
Teams often classify schema management and DLQ policy as governance overhead. That is the wrong category. In EDA, governance defines whether the system can absorb change without causing hidden breakage.
A schema registry limits the blast radius of payload changes. Correlation IDs preserve causality across service boundaries. DLQ ownership determines whether failed events are reviewed, replayed, or discarded. Telemetry standards decide whether platform teams can compare failures across domains instead of debugging each service as a one-off system. Teams that treat these controls as optional usually discover the cost during the first multi-team incident, not during architecture review.
A practical baseline looks like this:
- Attach a correlation identifier to every event and preserve it across retries, enrichments, and fan-out paths.
- Review schema changes like code releases because payload drift creates production incidents, not just compatibility warnings.
- Assign named ownership for DLQ triage, replay rules, and retention windows.
- Standardize logs, metrics, and traces early so the platform can support observability requirements in modernized distributed systems without custom debugging per team.
A simple test works. Pick one failed business transaction and ask for the full event path, the schema version involved, the retry history, the DLQ status, and the exact consumer that broke the flow. If your team cannot answer in minutes, the architecture is still carrying hidden operational debt.
The CTO Decision Checklist Is EDA Modernization Defensible
This is the filter that saves money.
Not every legacy system should become event-driven. Some should be stabilized, containerized, or selectively refactored without introducing a full asynchronous backbone. A defensible decision starts by rejecting EDA where the problem doesn’t warrant it.
Green lights
Proceed when most of these statements are true:
- The business needs fast reaction to state changes. Batch or delayed synchronization is no longer acceptable.
- Multiple teams need to ship independently. Shared release cycles are slowing delivery.
- The system faces bursty demand or integration volatility. Buffered asynchronous processing solves a real operational problem.
- You can name clear domain boundaries. The monolith has extractable capabilities, not just tangled layers.
- You’re willing to fund observability and contract governance up front. Not later.
Red lights
Stop when these conditions dominate:
- Event volume is low enough that simpler integration patterns are sufficient.
- The main issue is code quality, not coupling or reaction speed.
- Your team lacks distributed systems debugging discipline and won’t invest in it.
- You can’t support schema governance, tracing, and DLQ operations from day one.
- Leadership wants a rewrite narrative more than a risk-managed modernization path.
Final test
Ask four blunt questions in the approval meeting:
- What business capability becomes materially better because events propagate asynchronously?
- Which domain gets extracted first, and why is that boundary stable?
- How will we detect schema breakage, duplicate processing, and failed consumers before customers do?
- Who owns runtime governance after go-live?
If those answers are vague, the program isn’t ready.
EDA is powerful when the business needs speed of reaction, organizational decoupling, and resilience under real load. It’s a mistake when teams use it to compensate for weak system design or to signal architectural ambition.
If you’re evaluating event-driven architecture modernization and need a clearer read on risk, implementation trade-offs, and when not to proceed, Modernization Intel publishes research for technical leaders making defensible modernization decisions.