
Data Lake vs Data Warehouse Modernization: A CTO's Decision Guide
The choice between modernizing a data warehouse and pivoting to a data lake is not an upgrade—it’s a strategic fork in the road. One path optimizes your existing BI and structured analytics. The other is a fundamental shift to handle every data type imaginable, positioning you for a future dominated by AI and machine learning.
This decision dictates whether you’re building a faster horse or inventing the automobile. The wrong choice leads to a multi-million dollar platform that fails to deliver business value.
The Modernization Imperative: Why This $50B Decision Matters Now
This is not a simple technical refresh. This is a high-stakes infrastructure bet forced by the structural failure of legacy systems to manage modern data velocity and variety. Understanding the landscape of modernizing legacy systems is the first step, but the data platform is where real value—or liability—is created.
Traditional data warehouses, with their rigid schema-on-write architectures, are cracking under the weight of unstructured and semi-structured data, which is exploding at a rate of 40-50% annually in most enterprises. This forces a decision that will define your company’s analytical and AI capabilities for the next decade.
The global Data Lake & Warehousing Market, valued at USD 16 billion in 2024, is projected to hit USD 50 billion by 2030. This explosive growth is driven by a mass exodus from costly on-premises systems—which can still run $5-10 million for petabyte-scale setups—to more agile cloud platforms that now own 75% of the market.
Executive Summary: Data Warehouse vs. Data Lake Modernization
For a CTO or VP of Engineering, this isn’t about picking the “better” technology. It’s a cold assessment of business goals against architectural realities. The right choice aligns with your data strategy, cost model, and, most importantly, your revenue-generating use cases.
The table below breaks down the two modernization paths across the critical dimensions.
| Dimension | Data Warehouse Modernization (e.g., to Cloud Warehouse) | Data Lake Modernization (or shift to Lakehouse) |
|---|---|---|
| Primary Goal | Optimize and scale existing BI, reporting, and structured analytics. | Enable advanced analytics, AI/ML model training, and exploratory analysis on diverse, raw data types. |
| Data Structure | Primarily structured data. Schema-on-write enforces a rigid structure upon ingestion. | All data types: structured, semi-structured, and unstructured (e.g., logs, images, text, audio). |
| Cost Model | Generally higher compute costs, but optimized for query performance. Often licensed by node or query volume. | Lower storage costs (~$0.023/GB/month). Compute is decoupled and paid for on-demand. |
| Typical Use Cases | Financial reporting, sales dashboards, historical performance tracking, and operational analytics. | Predictive modeling, real-time analytics, fraud detection, LLM training, and R&D data exploration. |
| Key Risk | Vendor lock-in and schema rigidity that locks you out of future use cases beyond standard BI. | The “data swamp”—a high risk of failure if governance and metadata management aren’t established from day one. |
A warehouse modernization is a tactical move to improve what you already do. A shift to a data lake or lakehouse is a strategic play, betting that the value of your future data—most of which is unstructured—will dwarf the value of your current data.
Choosing Your Modern Architecture: Warehouse vs. Lake vs. Lakehouse
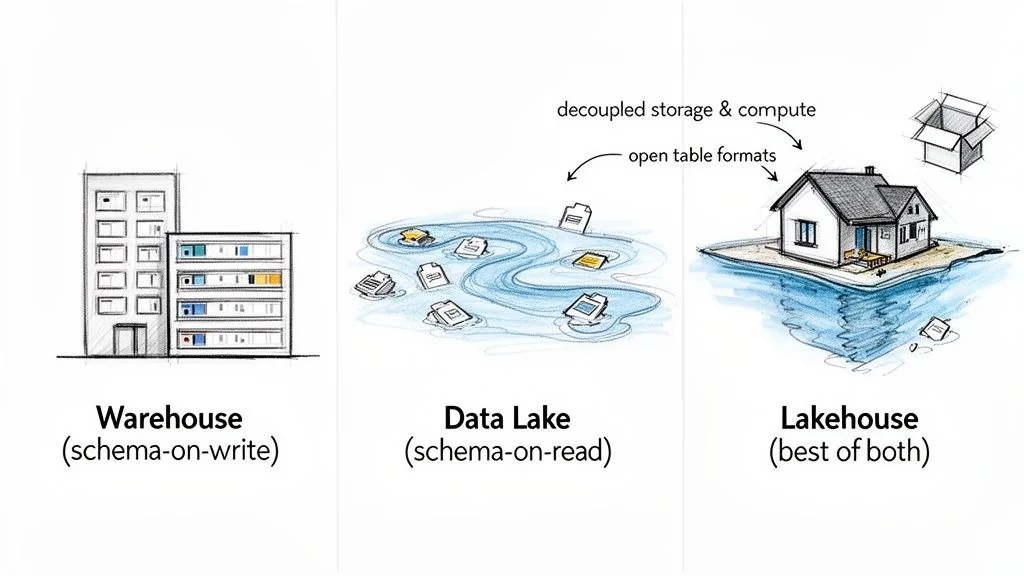
The choice between a warehouse, lake, and lakehouse dictates how you handle data structure, governance, and analytics, directly impacting your total cost of ownership and ability to compete on data-driven insights.
The fundamental conflict is between schema-on-write (the data warehouse) and schema-on-read (the data lake). A modernized cloud warehouse demands a rigid, predefined schema before data is written. This guarantees blazing-fast, reliable performance for known BI queries and executive dashboards. In contrast, a data lake ingests everything—structured, semi-structured, and raw files—with no upfront schema enforcement. This raw flexibility is essential for data science and machine learning, where value is discovered through exploration, not predefined reports.
The Lakehouse Architecture: A Pragmatic Hybrid
The Lakehouse isn’t a new product. It’s an architectural pattern that surgically combines the strengths of both worlds. It implements warehouse-style data management and governance directly on top of the cheap, flexible object storage of a data lake, eliminating the data silos that inevitably form between separate systems. Decoupling compute and storage is the key enabler, letting you scale query processing power and data storage independently for massive cost-optimization.
The real innovation of the lakehouse is its ability to deliver ACID transactions, data versioning, and schema enforcement—features once exclusive to warehouses—on open-source data formats. This prevents vendor lock-in and creates a unified platform for both BI and AI.
This model is gaining traction because it solves the classic pain points of warehouse modernization projects, which routinely run 20-40% over budget due to brutal ETL complexity. Understanding the foundational differences is non-negotiable. Grasping the Database Vs Data Warehouse Vs Data Lake Difference is a prerequisite to making an informed decision.
Open Table Formats: The Engine of the Lakehouse
The magic behind the lakehouse lies in open table formats like Apache Iceberg, Apache Hudi, and Delta Lake. These formats add a metadata transaction layer over raw data files in your lake, enabling reliable, high-performance SQL queries on petabytes of data.
- Apache Iceberg: The emerging industry standard, known for its bulletproof schema evolution and powerful time-travel capabilities. It lets you change table schemas without costly data rewrites—a huge operational win.
- Delta Lake: The original lakehouse format, offering battle-tested ACID transactions and deep integration within the Databricks ecosystem.
- Apache Hudi: Focuses on fast data ingestion and updates (upserts), making it a strong choice for streaming and change-data-capture (CDC) workloads.
The lakehouse platform market is projected to grow from $12.58 billion in 2026 to $27.28 billion by 2030. Standardizing on a platform with robust, multi-cloud support for Iceberg can prevent a costly rework down the line, saving an estimated $1-3 million on a complex project.
Building a Realistic Modernization Budget
Flawed budgets, born from vendor optimism and a failure to account for hidden complexities, are the leading cause of stalled initiatives and massive overruns. A defensible budget is not a single number; it’s a transparent breakdown of the total cost of ownership (TCO) for each path. Budget overruns of 20-40% are the baseline, not the exception.
Data Warehouse Modernization Cost Factors
Moving a traditional data warehouse to a cloud-native equivalent like Snowflake, Amazon Redshift, or Google BigQuery is not a “lift and shift.” You trade on-premise hardware headaches for a more complex set of expenses.
Model these real costs:
- Compute, Not Storage: Your bill is driven by compute. You pay a premium for processing power that delivers fast queries. Underestimate your query patterns, and your costs will spiral.
- Specialized Talent: The market for experienced DBAs and warehouse architects who understand these new platforms is tight. Their salaries are a significant, recurring operational cost.
- The ETL Rewrite Tax: This is the killer. Your existing ETL pipelines almost never work efficiently in the new environment. Expect to rewrite nearly everything. This is a labor-intensive, high-risk, and expensive task that initial budgets dramatically underestimate.
Data Lake and Lakehouse Cost Analysis
The cost model for a data lake or lakehouse shifts the budget from monolithic licensing fees to a granular, pay-as-you-go structure, which demands rigorous management.
The core economic promise of a data lake is storing data for roughly 1/10th the cost of a structured warehouse. This saving is a mirage without airtight governance. We’ve seen “data swamp” cleanup projects run anywhere from $500K to $2M—a cost that completely negates any storage savings.
Your budget must have explicit line items for:
- Cloud Storage: At ~$0.023/GB/month, it’s cheap on paper, but this is a volume game. At terabyte or petabyte scale, these costs accumulate.
- Data Ingestion: A frequently underestimated expense. Project data shows ingestion costs range from $1.50 to $4.00 per GB, depending on source complexity and tooling.
- On-Demand Compute: You pay for every query, ETL job, and model training run. Without constant monitoring and cost attribution, compute spend can become the biggest line item on your cloud bill.
- A New Kind of Talent: The focus shifts from DBAs to data engineers and governance specialists who can build resilient pipelines and enforce the rules that prevent your lake from turning into a swamp.
Cloud-based data platforms now command 75% of the market share because legacy systems cannot compete on scalability or cost-efficiency. The data lake market alone is projected to hit $31 billion by 2026. Building a budget that ignores these realities is negligent. For a deeper dive into these trends, review the latest data lake statistics.
Common Failure Modes and How to Mitigate Them
Most modernization projects don’t fail with a bang; they die a slow death from unaddressed risks. For comparison, adjacent fields like COBOL projects still see failure rates as high as 67%. Success requires anticipating failure before it happens. Ignoring the predictable failure modes of your chosen path is the fastest way to burn your budget and deliver zero business value.
The Data Lake’s Descent into a Swamp
The classic data lake failure is the “data swamp.” This is not a technical glitch; it is a complete failure of governance. Our analysis shows that 40-50% of data lake initiatives devolve into unusable, ungoverned repositories, wasting millions. It happens when teams get obsessed with ingestion speed while treating quality and metadata as a “phase two” problem.
To prevent this, be disciplined from day one:
- Implement a Data Catalog from Day One: A catalog that automatically captures metadata and tracks lineage is your only defense against chaos. It is not optional.
- Enforce Data Quality at the Gate: Automate data quality rules within your ingestion pipelines. Quarantine data that fails to meet minimum standards, do not dump it into the lake.
- Establish Granular Access Controls: Define clear, role-based access controls (RBAC) to ensure people only access data they are supposed to. This prevents misuse and ensures compliance.
Warehouse Modernization Pitfalls
Modernizing an enterprise data warehouse to a cloud-native platform like Snowflake or BigQuery fails because the migration’s complexity is grossly underestimated.
The single biggest point of failure in warehouse modernizations is the ETL rewrite. Teams assume they can “lift and shift” existing logic. The reality is that it’s a near-total rewrite that uncovers schema mismatches, creates new performance bottlenecks, and adds massive, unbudgeted labor costs.
Common failure points include:
- Schema Rigidity Lock-In: Migrating to a new cloud warehouse without redesigning your schema for future needs just moves an old problem to a newer, more expensive home.
- Vendor Lock-In: Choosing a proprietary cloud warehouse without a clear exit strategy is a critical mistake. Build your architecture on open formats (like Apache Iceberg or Parquet) to retain control over your data.
- Performance and Cost Spirals: Naively migrating queries without re-architecting them for the new platform’s compute and storage model is a recipe for slow performance and runaway costs.
Anticipating these failure modes is foundational. Our comprehensive guide on legacy system modernization provides more actionable strategies for navigating these challenges.
A Decision Framework for Your Data Platform
Choosing the right data platform is a strategic commitment with a seven-figure price tag. The decision between modernizing a data warehouse, building a data lake, or adopting a Databricks lakehouse architecture must be driven by a cold assessment of your business drivers and financial reality, not vendor hype.
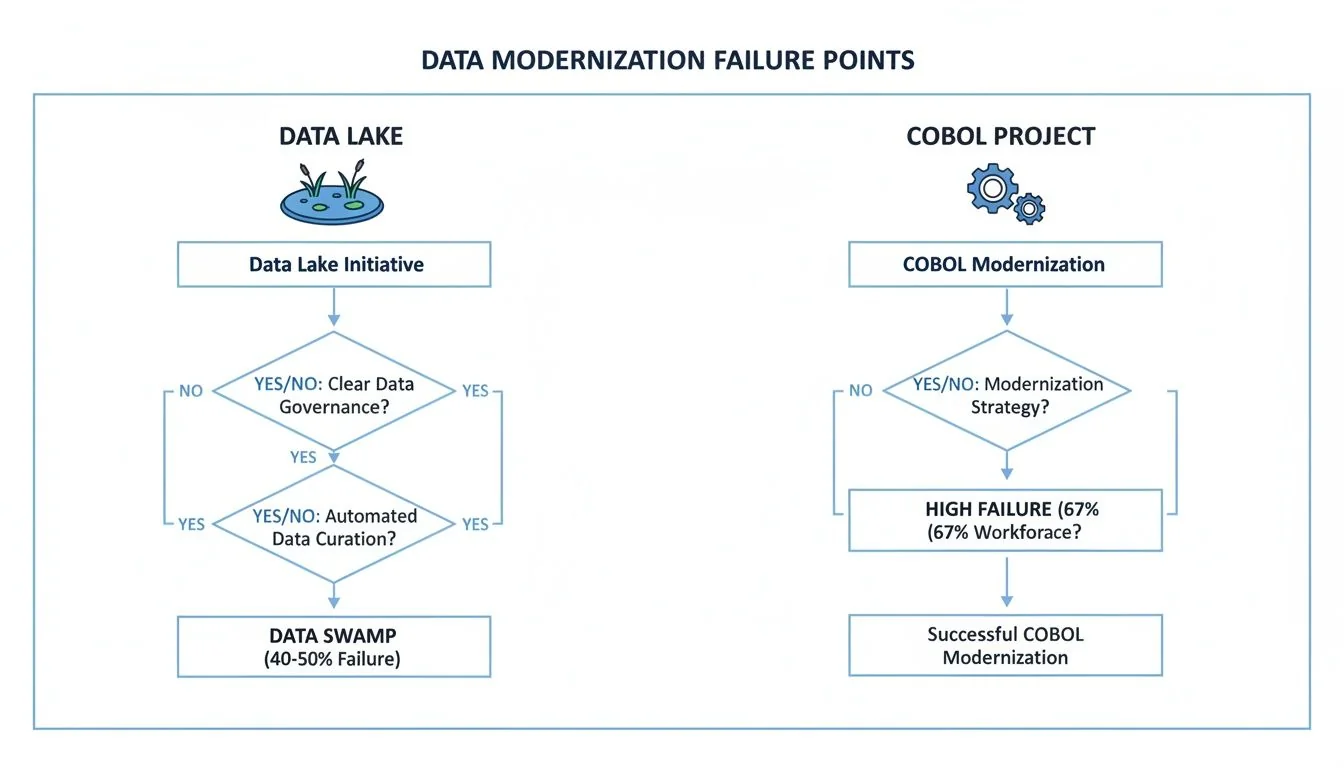
Both legacy and modern data projects fail, but for different reasons. The data lake’s primary failure mode—the data swamp—is a direct result of weak governance, a factor you must control from day one.
Data Platform Modernization Decision Matrix
This matrix forces a decision based on your organization’s specific context, not generic pros-and-cons. Map your actual requirements to the architectural path that delivers.
| Decision Driver | Choose Data Warehouse Modernization If… | Choose Data Lake Modernization If… | Choose Lakehouse Modernization If… |
|---|---|---|---|
| Data Structure | Your data is over 90% structured and will stay that way. Primary inputs are transactional databases and structured files. | You have a large and growing volume of unstructured or semi-structured data (text, logs, images, IoT). | You must govern and analyze a mix of structured, semi-structured, and unstructured data in a single, unified system. |
| Primary Use Case | Your core need is BI, financial reporting, and operational dashboards with sub-second query performance on known questions. | Your focus is exploratory data science, AI/ML model training, or R&D where data schemas are undefined at ingest. | You need to support both BI reporting and advanced analytics/AI on the same data without creating silos or duplication. |
| Query Performance | You need consistent, sub-second query latency for a high number of concurrent users running predictable reports. | You can tolerate variable query performance. Ad-hoc, exploratory queries are the norm, not high-concurrency BI. | You need fast BI query performance on curated data, plus flexibility for exploratory queries on raw data, all in one platform. |
| Scalability | You need to scale compute and storage together for predictable, structured workloads. | You must scale storage and compute independently. Data volume growth dramatically outpaces query workload growth. | You require independent scaling of storage and compute, using cloud elasticity for both BI and AI workloads. |
| Budget Model | Your budget is optimized for predictable, often CapEx-like, operational spend on compute and licensing. | Your budget model is pure OpEx, focused on minimizing storage costs and paying for compute on an on-demand basis. | You have a sophisticated OpEx budget model and can manage variable compute costs across different workload types. |
| In-House Skillset | You have a strong team of DBAs and BI developers skilled in SQL and traditional data modeling. | You have a team of data engineers and data scientists proficient in Python/Scala, Spark, and distributed systems. | You are building a blended team of data engineers, analytics engineers, and data scientists who can work across SQL and code. |
If you cannot clearly answer these questions, you are not ready to invest millions in a new platform.
When to Skip Modernization
Modernization is not a universal mandate. Resisting pressure to modernize for its own sake is a sign of mature technical leadership.
The most compelling reason to not modernize is when your existing data warehouse already meets 100% of its business objectives with acceptable performance and cost. If it is not broken, and you have no strategic imperative for unstructured data analytics, “fixing” it is a high-risk, low-reward endeavor.
Do not proceed with modernization if:
- Your data is over 90% structured, and your query needs are static and predictable.
- The primary use case is internal historical reporting, with no business demand for predictive analytics or AI/ML.
- Your current system’s TCO is manageable, and a migration would introduce cost uncertainty without a clear ROI.
- Business sponsors cannot articulate a specific, revenue-generating outcome that the new platform would enable.
In these cases, a modernization project becomes an expensive solution in search of a problem.
Your Modernization Execution Playbook
The decision is made. Execution is now the challenge. This is not a single project; it is a multi-phase program where scope creep and budget overruns are the default. This playbook provides a plan to move from strategy to successful, phased implementation.
Step 1: Evaluate Vendors and Partners
Picking the right implementation partner is your first tactical move. The skills for a cloud warehouse migration are fundamentally different from those for a lakehouse build-out.
- For Cloud Warehouse Modernization: Look for partners with deep expertise in your target platform, whether it’s Snowflake, BigQuery, or Microsoft Fabric. Demand case studies where they have cut costs by 50% or boosted performance 4x, like Kantar’s migration to Microsoft Fabric.
- For Data Lake/Lakehouse Modernization: Here, you need data engineering specialists. Seek experts in platforms like Databricks or those who build custom solutions with open table formats like Apache Iceberg. Their core competency must be Spark optimization, robust data pipeline construction, and implementing governance frameworks.
Step 2: Build a High-Impact Pilot Project
Do not attempt a “big bang” migration. The risk is astronomical. Instead, scope a small, high-impact pilot project that can be delivered in 90-120 days. The ideal pilot targets a single business domain or use case that is actively failing on your legacy system. The goal is to prove tangible value, validate architectural bets, and build momentum.
A pilot is not a throwaway proof-of-concept. It is the first production-ready piece of your new data platform. Build it with the same rigor and governance as the final system, as it will establish the patterns all future workloads will follow.
Step 3: Establish Governance from Day One
The greatest threat to your data lake or lakehouse is treating governance as a “Phase 2” problem. Pushing metadata management, data quality, and access control down the road is a guaranteed way to build a data swamp.
Your execution plan must treat these governance tasks as non-negotiable deliverables for Phase 1:
- Deploy a Data Catalog: Automate metadata discovery and lineage tracking for every data source in the pilot. If it’s not cataloged, it doesn’t exist.
- Automate Data Quality Rules: Implement data quality checks directly within ingestion pipelines. Quarantine bad data before it touches the lake.
- Define Role-Based Access Controls (RBAC): From the moment the first byte of data lands, access must be strictly controlled, auditable, and based on the principle of least privilege.
This proactive stance is the critical difference between a successful modernization and another costly, failed IT project.
Frequently Asked Questions
These are the direct answers to the high-stakes questions that executives ask when weighing a data warehouse modernization against a lakehouse.
How Is Data Governance Enforced in a Lakehouse?
In a traditional data warehouse, governance is a side effect of its rigid schema. In a lakehouse, governance must be engineered into the platform from day one.
Effective lakehouse governance rests on three non-negotiable pillars:
- A Unified Data Catalog: This is the brain of the operation. It must automatically discover, tag, and track the lineage of every data asset. Without it, you have a data swamp.
- Open Table Formats: This is the technical backbone. Technologies like Apache Iceberg or Delta Lake bring warehouse-grade reliability to low-cost object storage, enabling ACID transactions, schema enforcement, and time-travel (versioning) directly on the lake.
- Fine-Grained Access Control: Modern frameworks allow attribute- and role-based access controls (RBAC) down to the individual row and column level. This delivers security and meets compliance mandates without creating useless data silos.
Governance in a lakehouse is a deliberate act of engineering, not a feature you switch on.
What Is a Realistic Timeline for a Phased Migration?
A “big bang” migration is a known anti-pattern. A phased approach that breaks the project into manageable stages, each delivering clear business value, is the only strategy that works.
A typical phased migration timeline:
- Phase 1 (Months 1-3): Foundation & Pilot Project: Isolate a single, high-impact business use case. Lock in your platform choice, establish foundational governance, and push the first workload to production. A win here is critical.
- Phase 2 (Months 4-9): Migrate Core Workloads: Move the next 2-3 business-critical workloads. This phase refines migration patterns and builds muscle within your data engineering team.
- Phase 3 (Months 10-18+): Scale & Decommission: With proven patterns, accelerate the migration of all remaining workloads. The primary goal is to start shutting down legacy systems to realize cost savings.
While a full enterprise migration can take 18-36 months, your goal must be to deliver tangible business value within the first quarter. This iterative model kills the two biggest project risks: losing momentum and analysis paralysis.