
Modernization Is Business Reinvention, Not Just Code Swaps
When someone says “technology modernization,” most people think of a simple rip-and-replace job. That definition is obsolete. For 2025, technology modernization is a systematic overhaul of legacy systems into AI-native, resilient architectures.
This isn’t an IT project; it’s a full-scale business reinvention designed to drive 30–50% efficiency gains. This strategic shift is why 99% of IT leaders are prioritizing it, fueling a global digital spend that has surpassed $2.5 trillion.
Redefining Modernization for 2025
So, what is technology modernization, really? It’s the strategic process of transforming your outdated, fragile systems into agile, efficient, and secure platforms. The goal is to get way beyond just “keeping the lights on.”
The real objective is building a technical foundation that directly speeds up the business, creates competitive moats that are hard to copy, and unlocks entirely new ways to make money. This isn’t just an IT project buried in the basement; it’s a C-suite imperative where every technical improvement must be directly linked to a measurable business outcome.
From Cost Center to Value Driver
The fundamental mind-shift is to stop seeing technology as an operational expense and start treating it as the primary engine for growth. Legacy systems are a constant drag on the balance sheet, showing up as real, quantifiable losses. Think of the $5 million per year a company hemorrhages in outage costs or the market share it gives up because product releases are painfully slow.
Modernization confronts these P&L hits head-on by targeting specific areas:
- Driving Serious Efficiency: The goal here is to lock in 30–50% efficiency gains by automating manual grunt work and killing off redundant infrastructure.
- Accelerating Timelines: Modern architectures are engineered to deliver a 20% faster time-to-market for new products, features, and customer experiences.
- Building Future-Proof Resilience: The architecture can’t be brittle. It has to be evergreen, ready to integrate future technologies like 2026’s quantum integrations without needing another round of costly, soul-crushing rewrites.
The table below breaks down how specific modernization efforts directly address common business frustrations and lead to concrete improvements.
| Modernization Driver | Legacy System Pain Point | Target Business Outcome |
|---|---|---|
| Cloud Adoption | High data center CapEx, slow server provisioning. | 30%+ TCO reduction, move from CapEx to OpEx, scale on demand. |
| Microservices | Monolithic app blocks fast feature releases. | 20% faster time-to-market, independent team deployments. |
| DevSecOps Automation | Manual testing & deployment, security vulnerabilities. | 50% reduction in release cycles, improved security posture. |
| Data Platform Modernization | Siloed data, slow reporting, no real-time insights. | Unlock AI/ML capabilities, data-driven decision making. |
Each driver is a lever you can pull to turn a technical weakness into a competitive strength.
Kick off with a C-suite workshop mapping legacy drag to P&L hits (e.g., $5M/year in outage costs). Charter a 24-month roadmap tying modernization to KPIs like 20% faster time-to-market.
The whole process kicks off by putting a price tag on inaction. A C-suite workshop is the right place to map every limitation of your legacy systems—be it downtime, security holes, or integration nightmares—to a specific financial impact. This data-first approach builds the undeniable business case, securing the executive buy-in you’ll need for a multi-year transformation. The focus is always on creating an unbreakable link between what’s being built and the value it delivers.
The Five Core Modernization Strategies
Picking a modernization path isn’t a one-size-fits-all decision. Get this wrong, and you’re on the fast track to a costly, over-engineered mess. The right approach hinges entirely on your business goals, risk appetite, and the real-world state of your legacy systems.
The most common framework for this decision is the “5 Rs,” a set of distinct strategies that range from a simple lift to a complete overhaul. Understanding these five options is the first step to building a modernization roadmap that you can actually defend in the boardroom. Each carries a different price tag, risk profile, and potential payoff.
Rehost: The Lift-and-Shift
Rehosting is the path of least resistance, often called “lift-and-shift.” It’s exactly what it sounds like: you move an application from an on-premise data center to a cloud IaaS provider with minimal—or zero—code changes.
Think of it as moving your belongings from one house to another without buying any new furniture. It’s fast, carries the lowest immediate risk, and it’s a great way to get out of a data center lease that’s coming up for renewal. But let’s be clear: a clunky monolith running on-prem will still be a clunky, expensive monolith in the cloud. It won’t magically start using cloud-native features like auto-scaling or serverless.
When NOT to use Rehost:
- If the app is already bleeding money to operate, moving it just moves the expense to your AWS or Azure bill.
- If your core goal is to boost performance, agility, or scalability, rehosting alone won’t get you there. It’s a location change, not a character change.
Refactor: The Lift-and-Reshape
Refactoring, or “lift-and-reshape,” involves making targeted, moderate changes to an application’s code to better fit the cloud environment, all without changing its core purpose. This is like reupholstering your old sofa—it looks and feels better, but it’s fundamentally the same piece of furniture.
You might containerize a few components or tweak the code to use a managed database service like Amazon RDS instead of a self-hosted one. It’s a pragmatic middle ground, unlocking some real cloud benefits without the terrifying cost and risk of a full rewrite. This is the sweet spot for apps that are important but don’t justify a ground-up rebuild.
Rearchitect: The Major Renovation
Rearchitecting is a major undertaking. Here, you’re fundamentally changing the application’s structure, most often by breaking a monolithic beast into a collection of nimble, independent microservices. This is like tearing down the walls in your house to create an open-concept living space. It’s a serious project that requires deep architectural expertise.
This is how you unlock maximum agility. Teams can develop, deploy, and scale individual services on their own timelines. It’s the right move for core business systems that need to evolve at the speed of the market. The rise of cloud computing, pioneered by platforms like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure, has made this strategy far more accessible than it used to be. You can explore the history of cloud innovation and its impact on modern enterprises to see how we got here.
When NOT to use Rearchitect:
- Avoid this for stable, low-value applications. The complexity and operational overhead can easily outweigh the benefits.
- Don’t even attempt it if your team lacks deep, hands-on microservices experience. You’ll just build a distributed monolith, which is the worst of both worlds.
Rebuild: The Ground-Up Construction
Rebuilding means you throw the old code away and start from scratch. You’re not renovating the old house; you’re bulldozing it and building a brand-new one on the same lot. This is easily the most expensive and time-consuming option, but it also provides total freedom to innovate.
You choose this path when an application is so choked with technical debt that any change is a nightmare, or when the business has pivoted so hard that the original system is simply irrelevant. This lets you build with modern languages, frameworks, and architectural patterns from day one.
Replace: The Move to a New Property
Finally, you can simply replace the old system. This means turning off the legacy app and swapping it out for a commercial off-the-shelf (COTS) or Software-as-a-Service (SaaS) solution. Think of it like selling your high-maintenance house and moving into a condo where all the upkeep is handled for you. A classic example is ditching a homegrown CRM for Salesforce.
This is often the smartest and most cost-effective move for commodity functions—things like HR, accounting, or customer support. Why build what you can buy? You offload the maintenance burden and get to ride the coattails of your vendor’s innovation.
The most critical mistake is assuming one strategy fits all applications. A successful portfolio modernization often involves a mix of all five Rs, carefully mapped to the business value and technical health of each system.
To help you start mapping your own applications, the table below gives a high-level comparison of these five strategies. Use it as a starting point for framing your own technology modernization decisions.
Modernization Strategies Comparison
| Strategy | Typical Cost (Per LOC/App) | Estimated Timeline | Associated Risk Level | Best For |
|---|---|---|---|---|
| Rehost | $0.25-$0.75 per LOC | 1-3 Months | Low | Fast data center exits; low-impact apps. |
| Refactor | $0.75-$2.00 per LOC | 3-9 Months | Moderate | Improving performance of core apps without major overhaul. |
| Rearchitect | $2.00-$5.00 per LOC | 9-24 Months | High | Breaking up critical monoliths for agility and scale. |
| Rebuild | > $5.00 per LOC | 18-36+ Months | Very High | Strategically vital apps where tech debt is crippling. |
| Replace | Subscription-based (SaaS) | 3-12 Months | Moderate | Commodity functions (e.g., HR, CRM) with viable market solutions. |
Each path has its place. The trick is to stop looking for a single silver bullet and start matching the right tool to the right job. A low-risk Rehost for a legacy internal tool might be just as smart as a high-investment Rearchitect for your customer-facing platform.
Building AI-First and Data-Ready Architectures
Bolting AI onto legacy systems is a recipe for failure. Real modernization means building for AI from the ground up, designing architectures where AI agents are embedded from day zero. As 70% of new applications now include AI/ML for predictive operations, this is the new standard.
The old playbook of tacking on an analytics dashboard is dead. Modern systems treat AI agents as first-class citizens. This means refactoring monoliths into microservices with embedded LangChain agents for autonomous scaling and using Flink streams for auto-remediation. These agentic workflows are slashing diagnostic times by 75%, but 40% of these projects fail without proper governance.
From Data Swamp to Data Ecosystem
An AI-first architecture is useless without a clean, accessible, and reliable data foundation. As 49% of enterprises prioritize cloud data modernization, the goal is to build a unified data ecosystem, not just databases.
This starts with unifying scattered data silos into a modern lakehouse architecture. Technologies like Delta Lake and Apache Iceberg are critical here, delivering query speeds up to 100x faster on petabyte-scale datasets. This makes the data actually usable for training AI models.
This decision tree gives you a simplified flow for figuring out the right path for a given application.
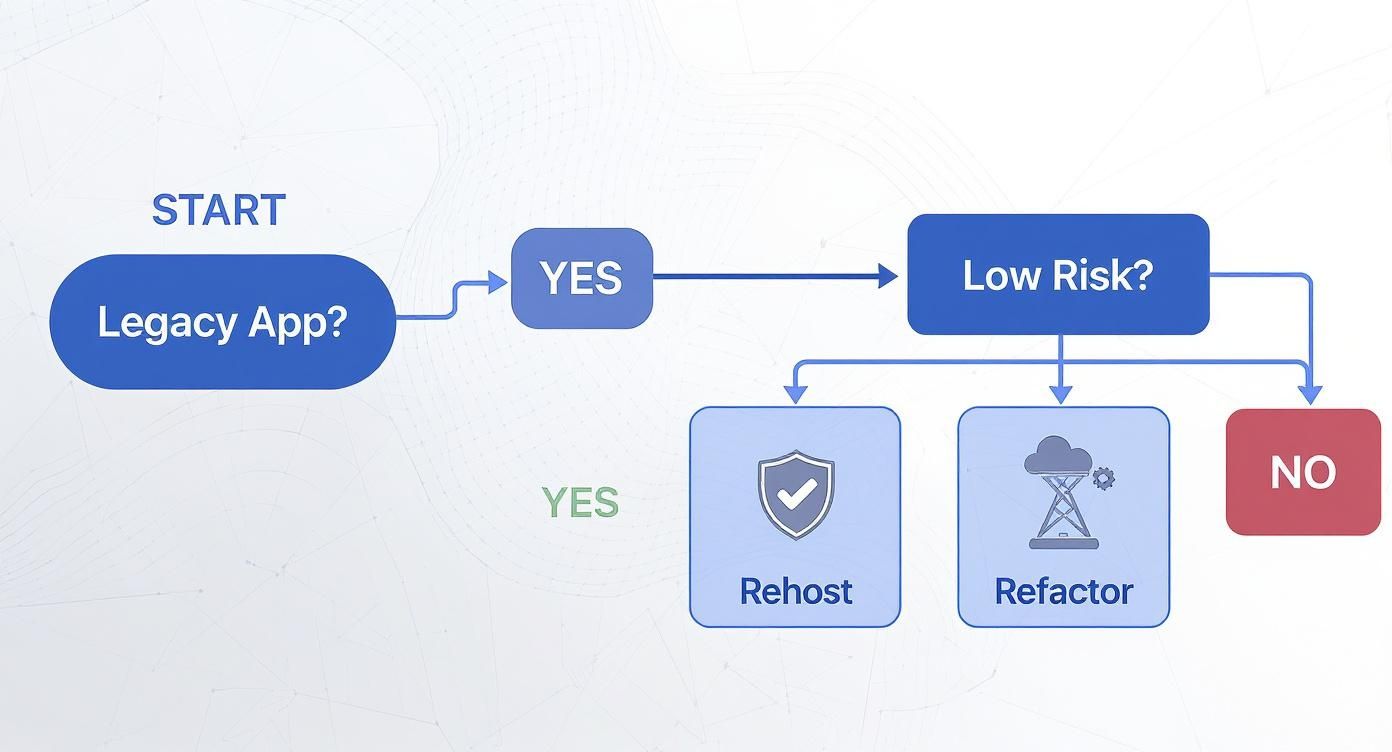
As you can see, the choice between a simple “lift and shift” (rehost) versus a deeper refactor often comes down to the application’s risk profile and how critical it is to the business.
Turning Data Overload into AI-Ready Insights
To manage modern data volumes, you need robust ELT pipelines. A modern data stack uses Airflow for orchestrating workflows and dbt for handling transformations, all feeding into a unified storage layer like Amazon S3.
A data ecosystem without enforced quality standards is just a data swamp. Embedding data SLAs, like ensuring less than 0.1% null values with tools like Great Expectations, is the guardrail that makes reliable AI possible.
Without these guardrails, you’re just training your AI on garbage data, which guarantees garbage results. Enforce AI ethics via Collibra audits in CI/CD. This unlocks massive ROI in ops savings and scales to edge AI without siloed retraining. You can explore our deep dive into the specifics of building a modern data platform in our article.
Modular Microservices: Break Monoliths for 3x Velocity
The final piece of this puzzle is breaking down those legacy monoliths. Enterprises are decomposing 80% of their stacks into smaller, API-driven modules to achieve 50% faster iteration cycles.
How do you actually do this without creating a distributed mess?
- Adopt contract-first design: Use specs like AsyncAPI to define service contracts before writing code. This prevents integration chaos later.
- Containerize everything: Package each service with Docker and manage the fleet with a service mesh like Istio to handle traffic management, security, and observability.
- Deploy progressively: Use tools like Helm to roll out changes to small user segments first, dramatically reducing the blast radius if something goes wrong.
This architectural pattern creates an evergreen foundation. You build composable applications that can adapt to 2026’s federated learning models without another painful, multi-year rewrite.
Why Modernization Projects Fail (And How to Make Sure Yours Doesn’t)
For all the talk of digital transformation, the uncomfortable truth is that most technology modernization projects are a slow-motion train wreck. This isn’t about one big, explosive failure; it’s a death by a thousand cuts—a series of preventable mistakes in strategy, talent, and execution.
Getting this right isn’t just about avoiding embarrassment. An honest look at the data shows that rudderless modernization efforts burn an average of 35% of their budgets on problems that were entirely avoidable. These aren’t rounding errors; they’re fundamental flaws that sink projects before they ever deliver a dime of value. Let’s get past the generic advice and look at the real-world pitfalls that kill these initiatives.
The Disconnect Between Technology and Business Value
The number one killer of modernization is strategic misalignment. A project that’s pitched as “we need to modernize our Java stack” is already doomed. It’s a solution in search of a problem.
Technical leaders absolutely must be able to answer the question: “How exactly will this $2.3 million Kubernetes migration reduce our customer churn by 5% or get our next product feature out the door a quarter sooner?” If you can’t draw a dead-straight line from the technical work to a P&L impact, you’ll lose your executive sponsor the second the CFO starts looking for things to cut. Your project will be seen as a cost center, an IT science fair project—not a strategic investment.
Failure Point: Modernization is treated as a pure technology upgrade, completely detached from measurable business outcomes like revenue, cost savings, or market share.
Countermeasure: Kick off every initiative with a C-suite workshop. The only goal is to map the financial drag of your legacy systems to specific, painful numbers (e.g., “$5M/year in outage costs from our monolithic checkout”). The output isn’t a tech spec; it’s a 24-month roadmap where every technical milestone is chained to a KPI, like hitting a 20% faster time-to-market.
The Crippling Technical Skills Gap
The second silent killer is the talent shortage. You can have the best strategy in the world, but if your team can’t execute, it’s just a PowerPoint deck. Modernization demands a tough, polyglot skillset—think DevOps, cloud-native architecture, and now, AI engineering. This skills gap delays 70% of projects.
The brutal reality is that a staggering 80% of teams are missing these critical skills. This is why up to 70% of modernization projects stall out, get delayed, or just quietly die on the vine.
Simply throwing consultants at the problem is a temporary, expensive band-aid that creates dangerous knowledge silos. The moment the consultants walk out the door, your internal team is left holding the bag on a complex new system they don’t understand. This isn’t a solution; it’s just renting expertise and creating long-term risk.
Actionable Steps to Close the Gap:
- Launch Internal Academies: Launch 12-week bootcamps on Kubernetes and dbt for 80% of your teams.
- Mandate Shadowing: Pair your internal engineers with external experts during migrations, tracked with GitHub Actions.
- Track with SLOs: Measure success by tracking improvements in key metrics. Set real SLOs, like aiming for a 50% faster deployment frequency for teams that have completed the academy.
This approach builds internal benches that slash consultant fees by 40% and endures beyond hype cycles.
Unchecked Scope Creep and Budget Overruns
Without ironclad financial guardrails, modernization projects are notorious for spiraling out of control. What starts as a plan to refactor a single application somehow morphs into a full-blown data center migration with no clear finish line. This is the primary driver behind that 35% budget waste figure we see across the industry.
The fix is to embed financial operations—FinOps—directly into your modernization workflow from day one. FinOps isn’t just about getting a cloud bill at the end of the month. It’s about creating a real-time feedback loop that connects every dollar spent to the value it creates.
Failure Point: Financial oversight is reactive. By the time you get the monthly report, the money has already been wasted.
Countermeasure: Cap modernization spending at 15% of the unlocked value it promises. To do this, you need real-time cost telemetry. Integrate billing into your lakehouse for real-time “cost per insight” telemetry. Tag every single cloud asset by business unit in a tool like Prometheus and pull that billing data into your data lakehouse. Then, use tools like Karpenter to automatically park idle resources, turning today’s waste into the funding for tomorrow’s AI pilots.
Navigating the Multi-Cloud and Security Landscape
The days of going “all-in” on a single cloud provider are over. By 2025, 94% of enterprises will be running a multi-cloud environment. This isn’t just about chasing the next big thing; it’s a strategic hedge.
Companies are deliberately spreading their workloads to blend public elasticity with private sovereignty, cutting vendor risks by 60% amid rising data regulations like GDPR 2.0. The trick is managing this distributed mess without creating total chaos. This is where Infrastructure as Code (IaC) becomes non-negotiable.
Ditching Lock-In for Sovereign Resilience
Use Terraform for IaC across AWS, Azure, and GCP. Federate queries with Trino on Iceberg tables. Instead of clicking through three different web consoles to configure environments, you codify everything—from VMs to networking rules—in files that live in your version control system.
This makes your entire setup repeatable, auditable, and, most importantly, portable. Prototype repatriation paths in four weeks to future-proof for 2026’s DePIN ecosystems, capping egress at <5% of your budget. This is a core part of a sound cloud architecture strategy. It’s about maintaining control.
Baking Zero-Trust Security into Every Refactor
Spreading your architecture across multiple clouds dramatically expands your attack surface. With 65% of breaches hitting legacy gaps, 2025 mandates mTLS and SPIFFE for hybrid flows, averting 90% of audit failures.
Security has to be an automated, mandatory part of the refactoring process from the very first line of code. This is the core idea behind a Zero-Trust model.
Zero-Trust assumes nothing and nobody is trustworthy by default. It demands verification from every single user and service trying to access your resources, shifting from a perimeter-based defense to a model of least-privilege access for every request.
This means you need rock-solid identity and access controls for every interaction, both within a single cloud and between your different cloud environments.
How to Implement Zero-Trust in the Real World:
- Mandate mTLS for All Service Communication. Use a service mesh like Istio to enforce mutual Transport Layer Security (mTLS). This forces every microservice to cryptographically prove its identity to any other service it talks to.
- Automate Runtime Security Audits. Mandate Falco runtime audits in ArgoCD rollouts to constantly monitor for anomalous behavior in your live environments.
- Simulate Attacks Quarterly. Use chaos engineering tools like Chaos Mesh to proactively run attack simulations against your own systems. This is how you find and fix vulnerabilities before someone else does. Layer in PII tagging via Soda SLAs. This adapts to post-quantum crypto without halting velocity.
When you embed these practices directly into your CI/CD pipeline, security stops being a bottleneck. It becomes an automated guardrail that lets your developers move fast without exposing you to the audit failures and legacy exploits that keep other tech leaders up at night.
Measuring Success with Velocity Metrics and FinOps
Modernization without measurement is just expensive busywork. It’s a shocking statistic, but 85% of initiatives stall because they lack feedback loops. Post-modernization SLOs are mandatory, or the project will fail.
This means we have to stop talking about project timelines and start tracking concrete, observable metrics that measure engineering velocity. Benchmark your deployment frequency and MTTR, targeting drops greater than 30%. Prune assets with less than 10% utilization quarterly.
Benchmarking with DORA Metrics
Instead of subjective status reports, you need hard data. The DORA metrics are the battle-tested framework for this, focusing on what actually matters for high-performing teams. These aren’t vanity metrics; they are the vital signs of your engineering organization.
Wire OpenTelemetry to Jaeger for end-to-end traces, alerting on regressions in PagerDuty. Track these four core metrics:
- Deployment Frequency: How often are you pushing code to production? A modernized architecture should get you to multiple deployments per day, not just per quarter.
- Lead Time for Changes: How long does it take for a developer’s commit to actually make it live? This is the true measure of your development lifecycle’s efficiency.
- Mean Time to Recovery (MTTR): When things break—and they will—how fast can you fix it? This is a critical indicator of your system’s resilience.
- Change Failure Rate: What percentage of your deployments cause a production failure? A low rate here means you’re shipping quality, not just speed.
The goal is a clear, quantifiable improvement. You should be aiming for a 30% or greater reduction in MTTR and a huge jump in deployment frequency within the first six months. Anything less suggests the investment isn’t delivering the promised returns.
Capping Costs with FinOps Guardrails
Velocity metrics are only half the story. They must be paired with ruthless financial discipline. Without it, a staggering 35% of modernization budgets get wasted on overprovisioning and scope creep. This is where FinOps comes in, acting as the essential guardrail that shifts IT from a cost center to a value generator.
The core principle is simple: cap your modernization spend at a percentage of the value it unlocks. A common rule of thumb is no more than 15%.
To enforce this, you need real-time “cost per insight” telemetry, not a monthly bill that arrives 30 days too late. This means integrating your billing data directly into your lakehouse and tagging every single cloud asset by business unit in a tool like Prometheus.
With this level of visibility, you can automate cost controls. A tool like Karpenter can automatically park idle resources, while proactive modeling helps you forecast what your spend will look like at twice the current volume. This isn’t just about saving money; it’s about turning waste into a self-funding mechanism for your next AI pilot. It also builds resilience to 2026’s carbon taxes.
To go deeper, our guide on cloud cost optimization strategies provides a detailed playbook. This is how you ensure every dollar spent on modernization is a defensible investment, not just a shot in the dark.
Tough Questions & Straight Answers on Modernization
Every tech leader I talk to has a few hard questions about modernization. They’re usually the same ones. Here are the honest, no-fluff answers.
”How do we even start this with no new budget?”
Don’t ask for a massive, multi-million dollar check. It’ll never get approved. Instead, you create a self-funding engine.
Find a legacy system that’s bleeding you dry. I’m talking about that one application server with a $1.2M annual license fee that everyone’s afraid to touch. Decommission it. Then, take 100% of those savings and immediately reinvest them into modernizing a system that actually drives revenue. You get a quick, tangible win, and suddenly the CFO is your new best friend.
”What’s the single biggest thing that derails these projects? (Besides the tech)”
It’s failing to connect your work to the P&L. Pitching a modernization project as a purely technical upgrade—“we have to get off Java 8”—is the fastest way to get your budget slashed at the first sign of trouble.
You have to chain every single technical goal to a business outcome. The goal isn’t refactoring a monolith into microservices. The real goal is achieving a 20% faster time-to-market for new features, which the refactor enables. Without that direct link, you lose executive support the moment they need to cut costs.
”Should we just hire consultants, or try to upskill our own people?”
Going all-in on consultants is a classic, expensive mistake. It creates a “shadow IT” department, leaves you with zero internal knowledge when they leave, and guarantees vendor lock-in.
The smart play is a hybrid model that prioritizes your own team.
Don’t outsource the core work. Instead, launch internal, 12-week bootcamps on the tech you’re adopting, whether it’s Kubernetes or dbt. Your goal should be to upskill 80% of your own engineers. Use consultants for what they’re best at: initial high-level architecture and coaching your team. This approach can cut your external consulting spend by over 40% and builds a capability that stays long after the SOW is closed.
”How do we actually know if any of this is working?”
Stop measuring success by “project complete” tickets. That’s vanity. The only thing that matters is velocity and business impact. Your new source of truth should be the DORA metrics.
If you’re not seeing a 30% improvement in metrics like Mean Time to Recovery (MTTR) or Deployment Frequency within the first six months, your investment isn’t paying off. A flat trendline is a massive red flag. It means you’re not getting the agility you paid for, and it’s time to have a hard conversation about the technical strategy.
At Modernization Intel, we give you the unbiased vendor intelligence needed for defensible modernization decisions. We map the real costs, failure rates, and specializations of over 200 implementation partners. Build your vendor shortlist based on data, not sales pitches. Get your vendor shortlist today.