
A Pragmatic Guide to Mainframe Exit Strategy Planning
A successful mainframe exit strategy doesn’t start with code. It starts with a brutally honest conversation about what “exit” means for your business. The goal isn’t a blind charge to abandon the platform, but a pragmatic, data-driven decision about which workloads belong where. It is about ensuring operational resilience and making a sound financial decision.
The Critical First Step: Kill the All-or-Nothing Myth
The all-or-nothing approach to mainframe modernization is a recipe for failed projects, blown budgets, and embarrassing cloud repatriations. For nearly every large enterprise, the real-world outcome is a hybrid model, not a complete evacuation. Your first, most critical job is to kill this binary thinking.
The industry is already waking up to this reality. Recent data shows a clear shift away from wholesale migration plans. Organizational plans to migrate most applications off the mainframe fell from 36% in 2024 to just 28% in 2025. That eight-point drop signals a trend toward pragmatic, workload-by-workload planning.
In fact, out of 500 organizations surveyed, only one intended a complete exit. This cements the hybrid model as the dominant—and most sensible—strategy. You can find more data backing this up in the latest mainframe modernization report.
Dismantling the Rewrite-Everything Fantasy
Before you call a single vendor or analyze a line of COBOL, your leadership team must agree on what success looks like. Is it reducing MIPS consumption by 40%? Or moving customer-facing applications to a more agile environment while leaving the core transaction processing system on the Z-series?
Without this clarity, teams default to the “rebuild everything” fantasy. That path is agonizingly slow, wildly expensive, and ignores that many mainframe applications perform perfectly. The 80/20 rule applies: roughly 80% of your mainframe applications require no functional changes, while only 20% are true candidates for a rewrite or replacement. Ignoring this is a direct path to budget overruns and operational chaos.
The most expensive mistake in mainframe modernization is solving a problem you don’t have. If an application is stable, performs its function, and doesn’t impede business agility, a full rewrite is a high-risk, low-reward endeavor. Focus your resources where they will deliver tangible business value.
This decision tree visualizes a more pragmatic way to think about it. You start with a high-level assessment of business criticality and technical debt, which then guides you to a logical path—either migration or a hybrid solution.
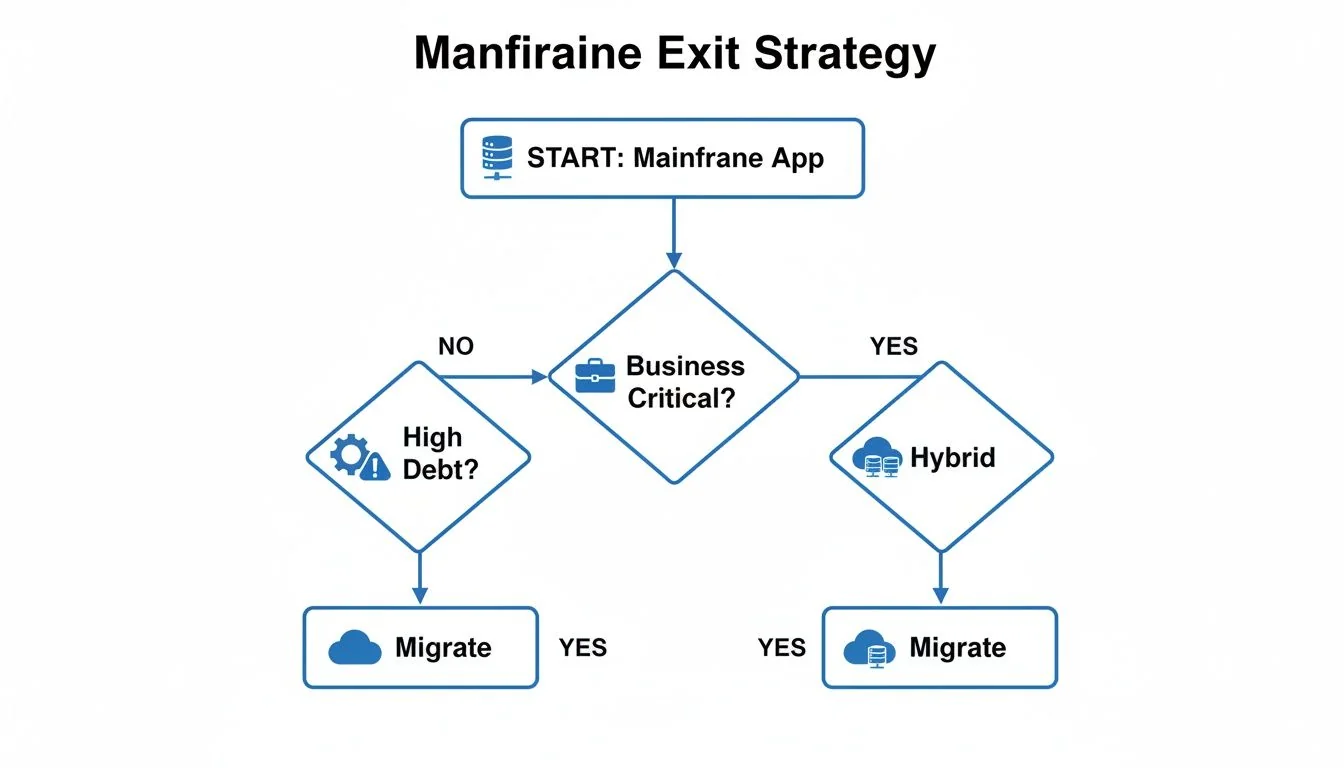
As the flowchart shows, the journey for every application does not automatically end in the cloud. A hybrid state is a valid—and often optimal—outcome for your most critical systems.
A Framework for Realistic Workload Classification
To get past gut-feel decisions, you need a structured framework. A workload classification matrix helps you categorize your application portfolio based on both business and technical drivers, forcing a more nuanced discussion that aligns IT efforts with business needs.
Start by creating a simple matrix to plot your applications and force a clear-eyed assessment of the right path for each one.
Workload Classification Matrix For Mainframe Exit Planning
This framework helps classify mainframe applications to determine the most viable modernization path based on key business and technical characteristics.
| Workload Profile | Business Criticality | Technical Viability for Migration | Recommended Exit Path |
|---|---|---|---|
| Core Transactional Systems | High (System of record, revenue-generating) | Low (Complex, high data gravity, deep integration) | Optimize/Retain. Focus on API enablement (Zowe) and cost reduction. Avoid migration. |
| Batch Processing | Medium (Critical but not real-time) | Medium (Often self-contained but large data volumes) | Re-platform/Automate. Move to modern schedulers or cloud-native batch services. |
| Agile-Dependent Apps | High (Customer-facing, needs frequent updates) | High (Often smaller, less entangled) | Rewrite/Replace. High-priority candidates for full modernization to microservices. |
| Legacy Reporting Tools | Low (Internal use, easily replaced) | High (Simple logic, low data volume) | Retire/Replace. Good candidates for replacement with a modern BI or analytics platform. |
This classification immediately separates the “must-moves” from the “leave-alones,” preventing you from wasting resources on low-value migrations.
To populate this matrix, evaluate each major application or workload against these core factors:
- Business Criticality: How essential is this application to revenue or core operations? A system processing billions in daily transactions has a different risk profile than a back-office reporting tool.
- Data Gravity: Where does the data live, and how hard is it to move? Applications with massive, complex DB2 or IMS databases and tight integrations are notoriously difficult migration targets.
- Regulatory Exposure: Does the application handle sensitive data subject to PCI DSS, GDPR, or HIPAA? The cost and complexity of proving compliance in a new environment are massive and cannot be an afterthought.
- Need for Agility: How often does the business need to change this application? Systems that must adapt to market demands are strong candidates for modernization. Stable, unchanging systems are not.
Charting Your Course: Migration Paths and Their Inevitable Failure Modes
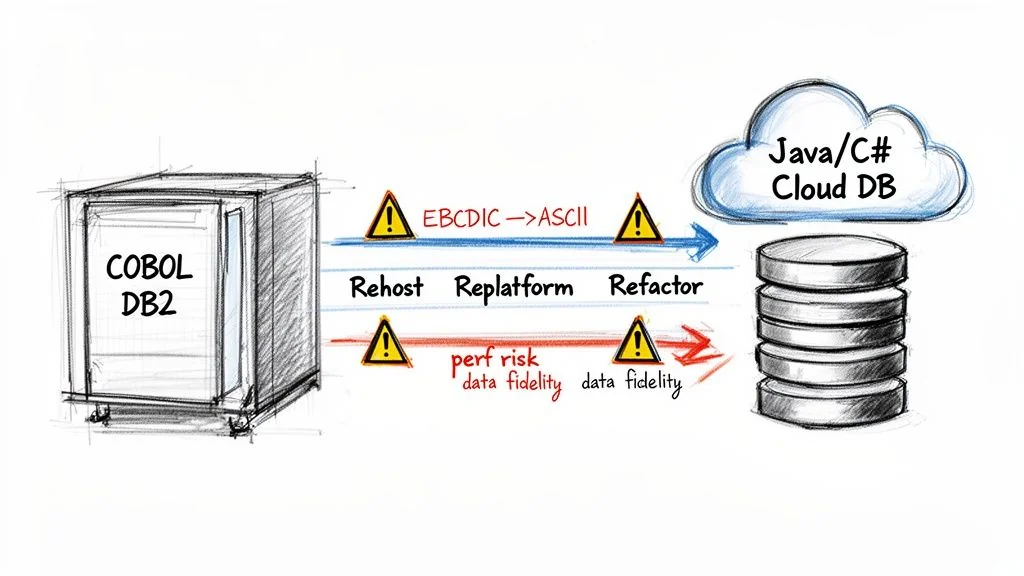
After sorting your workloads, it is time to map each application segment to a tangible technical migration path. We’re moving beyond vague labels like “Rehost” or “Rearchitect” and into the granular, often painful, realities of execution.
Every path has a unique risk profile and a well-documented set of failure modes. You must anticipate them.
Getting this wrong is effectively a permanent decision. Among companies that have completed a mainframe migration, a full 60% report that zero workloads ever moved back. This staggering ‘no return’ rate means a bad strategy or botched execution will have lasting consequences. Upfront diligence is an existential requirement.
Common Paths and Where They Go Wrong
Let’s dissect the three most common migration paths and where they typically break down.
-
COBOL to Java/C# Refactoring: This automated approach promises to convert your business logic into a modern language. The number one failure mode is catastrophic performance degradation. Automated tools produce verbose, inefficient Java or C# that is nearly impossible for a human to maintain. It does not map cleanly to COBOL’s highly optimized structure.
-
Database Migration (DB2 to Cloud-Native): Moving data from platforms like DB2 to cloud-native options like PostgreSQL is fundamental to any exit. Success hinges entirely on a flawlessly executed data transfer. This is why a deep understanding of data migration best practices is non-negotiable. The most devastating failure here is silent data corruption.
-
Data Replication for Hybrid Cloud: For any phased migration or long-term hybrid strategy, you need real-time data replication between the mainframe and the cloud. The primary failure mode is latency and data drift. Replication tools often choke on high-volume OLTP systems, leading to a state where your cloud environment is running on stale data. For any system that demands transactional consistency, this is a non-starter.
One of the most common pitfalls is underestimating the nightmare of character set conversion. Mainframes use EBCDIC; modern systems use ASCII/Unicode. A naive, bulk conversion will silently corrupt packed decimal fields (COMP-3), leading to subtle financial miscalculations that can go undetected for months.
This is not a theoretical risk. It is a leading cause of post-migration financial reconciliation failures that cost millions. The complexity of these moves is why organizations seek expert guidance on the broader legacy system modernization journey.
A Practical Risk Assessment Checklist
Use this checklist to turn these abstract risks into manageable action items. This should form the technical backbone of your RFPs and vendor evaluations.
Refactoring and Code Conversion Risks
- Performance Benchmarks: Does the vendor contractually commit to a performance SLA? For example, will refactored code execute with a response time within 110% of the mainframe baseline? Get it in writing.
- Code Maintainability: Demand to see a sample of the converted code. Is it clean, readable, and maintainable by a competent developer, or is it a mess of “transpiled” garbage?
- Decimal Precision: Ask them to prove how their tools handle COBOL’s COMP-3 packed decimal fields. Demand a specific demonstration showing how they prevent precision loss when converting to Java or C# data types.
Data Migration and Fidelity Risks
- EBCDIC to ASCII: What is the exact methodology for validating the EBCDIC to ASCII conversion? This must go beyond record counts and include checksums and field-by-field validation for your most critical datasets.
- Data Type Mapping: How will complex mainframe data types, like VSAM KSDS or IMS segments, be mapped to a relational model without losing their implicit relationships? A simple table dump is not sufficient.
- Data Reconciliation: What specific tools and processes will be used for a full, value-based reconciliation of critical data after the migration? “We’ll check the record counts” is not an acceptable answer.
Architectural and Security Risks
- Batch to Event-Driven: If you’re converting batch jobs, how will complex job dependencies and scheduling logic (your JCL) be replicated in the new architecture? A simple “lift-and-shift” often breaks this logic.
- Security Translation: How, exactly, will mainframe security rules from systems like RACF or ACF2 be mapped to cloud IAM policies? A failure here can create business-ending security holes in your new environment.
By forcing these hard questions early, you shift from a hopeful strategy to a defensible plan. The goal is to see the failure modes coming and build the contractual and technical guardrails to stop them.
Building a Defensible Cost Model, Not a Vendor Fantasy
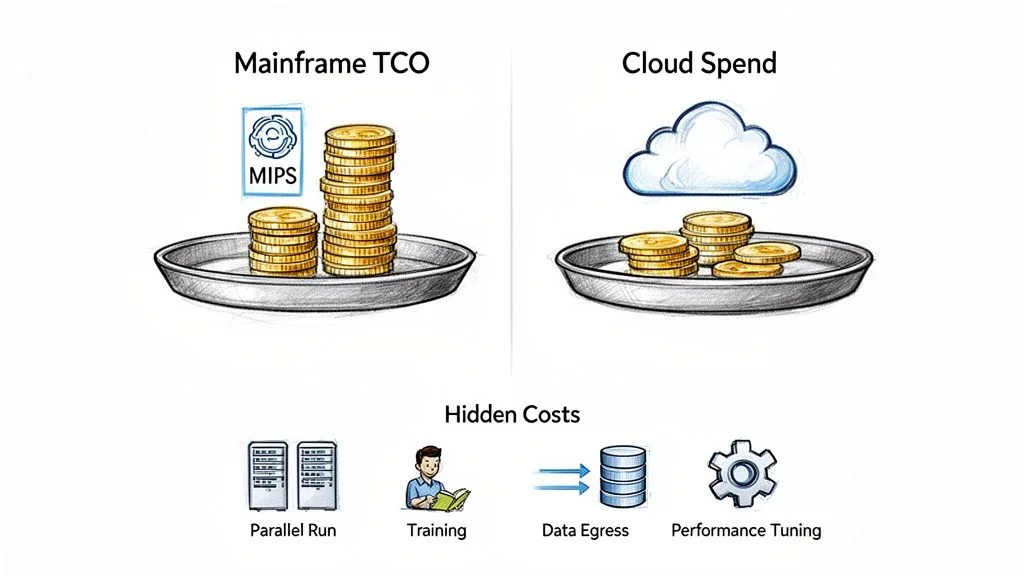
Any migration partner can show you a slide deck promising 30-50% savings by moving off the mainframe. The hard part is building a financial model that survives contact with reality.
A defensible plan requires you to build your own total cost of ownership (TCO) model—one that accounts for the painful, often hidden, truths of a complex migration. Do not rely on a vendor’s best-case scenario. Their TCO calculators are sales tools, notoriously optimistic about transition costs and cloud operating conditions.
This is why many modernizations are seen as failures. It’s not that they don’t work; it’s that they cost double what was promised, leaving you with severe sticker shock and a credibility gap with the business.
Beyond the Price Per Line of Code
Fixating on a single metric like cost per line of code is a classic mistake. While automated COBOL refactoring projects often fall between $1.50 to $4.00 per LOC, this is just the tip of the iceberg. The real budget-killers are the indirect and operational costs that vendors conveniently leave out of their initial quotes.
Your cost model needs to treat the migration as a multi-year program with distinct financial phases, not a one-off project.
A vendor’s estimate focuses on getting you to “go-live.” Your cost model must focus on the total expense of running the new system reliably for the next five years. The gap between those two numbers is where budgets are broken and careers are stalled.
To create a model that holds up, you have to rigorously quantify the “hidden” cost centers. These are non-negotiable expenses that will hit your budget.
Key Hidden Costs to Model:
- Parallel Run Expenses: This is the big one. For 6 to 18 months, you will pay for both the mainframe and the new cloud environment. This dual-cost phase is often the single largest unforeseen expense.
- Performance Tuning and Optimization: Your migrated application will not perform optimally out of the box. Budget for at least 3-6 months of post-launch performance engineering. This means significant cloud spend for scaled-up test environments and specialized engineers.
- Staff Retraining and Augmentation: Your mainframe team does not magically become a cloud-native DevOps team. Factor in extensive training and the high probability of hiring expensive cloud specialists to bridge the skills gap during the first 1-2 years.
- Data Egress Fees: This is the silent killer of cloud budgets. If your architecture requires moving large datasets out of your cloud provider’s network, these fees can accumulate with shocking speed. Model your data transfer volumes now.
- The Long Tail of Cloud Operations: Your cloud bill isn’t just compute and storage. It’s also monitoring tools, security services like WAF and threat detection, and CI/CD pipeline maintenance. These can easily add another 15-25% to your core infrastructure costs.
A Practical TCO Comparison Framework
To build a model that withstands CFO scrutiny, calculate your fully-loaded mainframe cost and compare it to a fully-loaded cloud projection. Do not just compare MIPS to vCPUs. For a more detailed breakdown of these expenses, see our guide to understanding the complete costs of legacy modernization.
This framework forces a more honest, apples-to-apples comparison.
| Cost Component | Fully-Loaded Mainframe Cost | Projected Cloud TCO (Year 1-3) |
|---|---|---|
| Hardware | Mainframe hardware lease/purchase, maintenance | Reserved Instances, On-Demand pricing, storage costs |
| Software | IBM software licenses (z/OS, DB2, CICS), ISV tools | Cloud provider services, new ISV licenses, SaaS tools |
| Labor | Mainframe specialists, operators | Cloud engineers, DevOps specialists, SREs, retraining costs |
| Transition | N/A (ongoing operations) | Parallel run costs, migration services, performance tuning |
| Indirects | Data center space, power, cooling | Data egress fees, cross-zone traffic, support plans |
By creating a multi-year plan that accurately reflects the investment required, you can secure the necessary budget and set realistic expectations. This is how you prevent the sticker shock that derails projects and undermines the credibility of your entire mainframe exit strategy.
How to Structure Vendor Contracts That Enforce Accountability
Your vendor contract is the single most important risk mitigation tool in your arsenal. A generic Master Services Agreement (MSA) won’t cut it. It offers zero protection against the unique, high-stakes failure modes of a mainframe migration. You need a bespoke contract engineered from the ground up to enforce accountability.
A properly structured agreement aligns your partner’s financial incentives directly with your project’s technical and business success. If they don’t deliver, it costs them real money.
Ditch Time-and-Materials for Milestone-Based Payments
The traditional time-and-materials model is a disaster for mainframe projects. It incentivizes your vendor to drag things out and throw more bodies at the problem. Your contract must shift payment from effort to outcomes.
This means structuring your payment schedule around concrete, verifiable deliverables. This simple but powerful shift moves financial risk from your balance sheet to theirs, forcing them to own the results.
Key Payment Milestones to Build In:
- Successful Pilot Completion: Payment is tied to the first migrated application running smoothly and hitting every predefined success metric.
- User Acceptance Testing (UAT) Passed: A significant payment tranche is released only after business users sign off, confirming functionality is 100% intact.
- Performance SLAs Met: Hold a portion of the final payment in escrow until the migrated system proves it can meet or exceed performance targets for a sustained period, like 30-60 days post-go-live.
This structure guarantees you only pay for tangible progress, not just billable hours.
Non-Negotiable Clauses for Technical Guarantees
Your legal team must work hand-in-glove with your enterprise architects to translate technical risks into contractual obligations. Vague promises of “high performance” are worthless. You need specific, measurable, and enforceable guarantees baked into the contract.
Your contract must be written for the worst-day scenario. Assume the project will go off the rails and the vendor will underperform. The clauses you add are the guardrails that bring it back on track or give you a clean exit.
Demand clauses that cover the most catastrophic failure modes of a mainframe migration. If a vendor pushes back hard on these terms, it’s a massive red flag. It shows they are not confident in their ability to deliver on their promises.
Example Performance Guarantee Clause: “Vendor guarantees that for the 90-day period following go-live, the average response time for critical online transactions (as defined in Appendix A) in the production cloud environment will not exceed 110% of the established mainframe baseline performance metrics. Failure to meet this Service Level will result in penalties as defined in Section X.”
Data Fidelity and Your Right to Walk Away
Data integrity is non-negotiable. Your contract has to specify the exact mechanism for validating data fidelity. Go beyond simple record counts and demand value-based reconciliation. At the same time, you need a pre-negotiated escape hatch if the relationship sours.
When structuring these agreements, it’s crucial to consider how they enable your own exit from the vendor relationship if needed. A key element is a clear termination clause in contract, which defines your pre-negotiated exit strategy and the terms for disengagement.
Your agreement must codify these critical protections.
| Contractual Clause | Purpose and Key Elements |
|---|---|
| Data Fidelity Validation | Mandates a field-by-field, value-based comparison of critical datasets between the source and target systems. It should specify the tools to be used and require vendor sign-off on 100% data integrity before final payment. |
| Penalty for Missed Deadlines | Establishes clear financial penalties for missing key milestones, such as a percentage of the milestone payment for each week of delay. This creates a powerful incentive for the vendor to stay on schedule. |
| IP and Work Product Ownership | Explicitly states that you own all converted code, scripts, configuration, and documentation generated during the project. This prevents a vendor from holding your modernized system hostage. |
By embedding these accountabilities directly into the contract, you transform it from a passive legal document into an active project governance tool. It sets crystal-clear expectations and gives you the leverage needed to keep your mainframe exit on track.
Next Steps: Build a Scalable Rollout Plan with a Pilot Project
A mainframe exit is not one giant leap; it’s a series of calculated, deliberate steps. Forget the “big bang” migration—that’s a high-stakes gamble destined for catastrophic failure. The only sane approach is a pilot-driven one, where you systematically de-risk the entire program and build a repeatable process.
The point of the pilot phase is not just to move one application. It is to build a blueprint for a “migration factory”—the assembly line that will eventually move dozens or even hundreds of workloads off the mainframe.
Selecting the Right First Mover
Choosing the first application for your pilot is a critical decision in the execution phase. The temptation is to pick the easiest, least important app. That’s a mistake. A trivial workload proves almost nothing.
Instead, the ideal pilot needs to be complex enough to be a meaningful test but not so critical that a hiccup creates a business-ending disaster. You are looking for a candidate that forces you to exercise your entire end-to-end process.
Look for these characteristics:
- Representative Technology: Does it use a common stack (e.g., COBOL, DB2, CICS) that you’ll see again in more complex systems? This validates your core technical approach.
- Toolchain Stress Test: Will it force your team to use the new CI/CD pipelines, code conversion tools, data migration scripts, and observability platforms?
- Architectural Proving Ground: Does migrating it validate your target cloud architecture, including its security model, network topology, and data access patterns?
- Balanced Risk Profile: Is it important to the business but not a Tier-0, customer-facing system? An internal application with a limited user base is often a perfect choice.
A common misstep is picking a simple, standalone batch job. A far better choice is a small online application with a few database tables and a moderate user base. This gives you a real-world test of performance, data integrity, and day-to-day operational readiness.
Defining Success Beyond “It Works”
“It works” is not a metric. The success criteria for your pilot must be ruthlessly quantitative and defined before you start. You need to build a scorecard with specific, measurable targets that act as a non-negotiable quality gate for every migration that follows.
A pilot that goes perfectly is almost as useless as one that fails completely. The ideal pilot surfaces painful, unforeseen problems—data conversion errors, performance bottlenecks, security gaps—in a low-risk context. Its real value is in the lessons learned, not in a flawless first run.
Your pilot scorecard should be grounded in reality, covering the domains that matter to the business.
| Metric Domain | Key Performance Indicator (KPI) Example | Success Threshold |
|---|---|---|
| Performance | Average transaction response time | Must be within 110% of the mainframe baseline. |
| Cost Accuracy | Monthly cloud operating cost | Must be within 15% of the pre-migration TCO model. |
| Operational Stability | Application error rate (post-launch) | Must be equal to or lower than the mainframe’s rate. |
| Data Fidelity | Reconciliation of critical data fields | Must achieve 100% value-based match with source data. |
Hitting these targets proves your technical approach is sound and your financial model is credible. Missing them tells you exactly where you need to adjust your strategy before you dare touch a more critical system.
From One-Off Pilot to a Migration Factory
The lessons you bleed for in the pilot are the raw materials for your migration factory. Once the pilot application is stable in production, you must conduct a thorough, no-ego post-mortem. Analyze every step of the process.
- What manual steps caused delays and can now be automated?
- Where did our cost or timeline estimates miss the mark, and why?
- What new, specific test cases do we need to add to our regression suite to catch the bugs we found the hard way?
The output of this analysis is a refined playbook: a collection of documented procedures, automated scripts, and standardized configurations. This playbook becomes the heart of your migration factory. When you move to the next application, you’re not starting from scratch. You’re executing a known, tested process. This is how your teams get faster and build momentum. Each subsequent migration industrializes the factory, turning your mainframe exit from a series of high-risk projects into a predictable, scalable program.
Common Questions About Mainframe Exit Strategy Planning
Even with the most detailed roadmap, tough, lingering questions will emerge. These are the practical realities that make or break these projects. Here are the straight answers to the questions we hear most often from technical leaders.
When Should We Absolutely Not Exit the Mainframe?
You hit the brakes on a full exit when a core application is a “black box.” We see this with decades-old financial systems where the original developers are gone and documentation is a myth. If the business risk of a single miscalculation is existential—think incorrect interest accrual across millions of accounts—a full migration is an unacceptable gamble.
The other hard stop is extreme performance. If your application has non-negotiable transaction throughput that’s either unproven or wildly expensive on the cloud, don’t do it. Some high-frequency trading platforms or core banking ledgers process volumes that are incredibly difficult and costly to replicate reliably in a distributed environment.
In these cases, a hybrid approach isn’t a compromise—it’s the only responsible strategy. Modernize the user-facing interfaces and build APIs around the core, but leave the processing engine on the metal where its performance and reliability are a known quantity.
How Do We Measure the True Success of a Migration?
Success is not “go-live.” True success is validated against a scorecard you defined upfront, tracking performance for at least 6-12 months after the cutover. A successful project proves your entire business case and technical strategy were sound.
Your scorecard must include these KPIs:
- Cost Realization: Is the new environment’s total cost of ownership (TCO) within 10-15% of your financial model? This confirms your business case wasn’t wishful thinking.
- Performance Parity: Are application response times and critical batch job windows matching or beating the mainframe baseline?
- Operational Stability: Is the new system’s uptime and error rate meeting or exceeding the mainframe’s legendary reliability?
- Functional Equivalence: Has 100% of the original business logic been replicated with zero functional regressions? This needs to be signed off by business users, not just the IT team.
Declaring victory before you have a year of data on these metrics is premature. It papers over long-term problems that will eventually surface.
What Is the Biggest Unseen Risk in Data Migration?
The biggest and most dangerous unseen risk is silent data corruption, almost always caused by character set conversion.
Mainframes use the EBCDIC character set. Cloud and modern systems use ASCII or Unicode. A naive, unchecked conversion process is a ticking time bomb for your data’s integrity.
This is especially treacherous with packed decimal fields (often called COMP-3), which are common in COBOL applications for financial calculations. An incorrect conversion can subtly corrupt these values, leading to catastrophic financial miscalculations. The worst part is you might not discover this for months, long after the original mainframe data is gone.
You need a specific, rigorous mitigation strategy for this. Your test plan must include a full, value-based data reconciliation using checksums and field-by-field validation for every critical dataset. Force your migration vendor to demonstrate—not just promise—their specific tools and expertise for handling these data types. Anything less is a direct threat to your business.