
A CTO's Guide to Mainframe Batch Processing Modernization
Modernizing mainframe batch processing is not a routine IT upgrade. It’s a direct response to escalating business risk and competitive pressure. The objective is to dismantle a rigid, overnight processing model and architect a responsive, event-driven system that feeds AI initiatives, slashes operational risk, and allows you to compete in a real-time data economy.
The Real Costs of “If It Ain’t Broke”

That legacy mainframe batch system is not a stable asset; it’s an escalating liability. The operational expense is the most obvious drain. Benchmarks show mainframe MIPS can be up to 4x more expensive than equivalent cloud workloads. But focusing only on the hardware bill misses the strategic crisis.
The real cost is competitive drag. Your core business logic is trapped in a nightly cycle, perpetually a day behind. While competitors leverage live data for instant decisions, you power modern AI and analytics platforms with stale information. This is no longer a sustainable position.
The Skills Gap Is Now a Chasm
This technical debt is colliding with a demographic cliff. The market for mainframe modernization services is projected to hit $75 billion by 2033, a surge driven by necessity, not choice. The experts who built and maintain these COBOL systems are retiring.
With over 80% of the COBOL workforce nearing retirement, you face a paralyzing reality: modernize or risk operational failure. This talent drain creates a dangerous dependency on a shrinking, and increasingly expensive, pool of specialists. Every day you delay, you contend with escalating issues with legacy code while the talent pool evaporates.
Maintaining the status quo is no longer a conservative choice; it’s a high-risk gamble. The “if it ain’t broke, don’t fix it” mindset ignores a brutal truth: a system that cannot support business agility is already broken.
The Business Case for Modernization Is Non-Negotiable
Deferring mainframe batch modernization is not saving money. It is an active decision to accept mounting risk and forfeit opportunity. The business case is built on three urgent pillars:
- Risk Mitigation: You must break the dependency on a retiring workforce and technology that vendors are quietly sunsetting. This is a business continuity imperative.
- Data Liberation: Your most critical business data is locked in batch silos. Unlocking it is the only way to power real-time analytics, train relevant machine learning models, and build responsive customer experiences.
- Architectural Agility: You must transition from brittle, monolithic batch jobs to a flexible, event-driven architecture. This is how you adapt to new business demands in hours, not months.
Ultimately, modernizing your batch processing turns a core operational bottleneck into the strategic engine that powers your company’s next phase of growth. The cost of inaction is a direct threat to survival.
Choosing Your Modernization Pattern: The Decision Framework
Picking the right modernization pattern for your mainframe batch jobs is the single most important strategic decision you’ll make. A wrong choice leads to budget overruns, blown timelines, and project failure. The right choice unlocks business value while managing risk.
This is not a one-size-fits-all decision. The optimal path depends on the specific batch workload.
The Five Core Modernization Patterns
The modernization playbook spans from simple infrastructure swaps to a complete rebuild of business logic. Your choice is a direct trade-off between cost, risk, and the agility you gain.
-
Rehost (Lift-and-Shift): This is the fastest and cheapest option. You move your batch jobs to a cloud environment, often using an emulator, with minimal code changes. The goal is infrastructure cost reduction, not a functional upgrade.
-
Replatform (Lift-and-Reshape): A step up from rehosting, this involves minor retooling to better fit the cloud, like swapping a DB2 database for a cloud-native database service. The core COBOL business logic remains unchanged.
-
Refactor (Automated Code Conversion): This pattern translates your existing codebase—like COBOL and JCL—into a modern language such as Java or C#. It leans heavily on automated tooling to preserve proven business logic, which is why it captures nearly 40% of the market. The goal is to escape expensive, proprietary mainframe tech while retaining your valuable business rules.
-
Rearchitect (Decomposition and Rewrite): A heavier lift where you break down monolithic batch applications into smaller, independent services, often for event-driven processing. This is the path to true agility, but it comes with significantly higher risk, cost, and complexity.
-
Replace (COTS/SaaS): This involves decommissioning the legacy batch application and switching to a Commercial-Off-The-Shelf (COTS) or Software-as-a-Service (SaaS) product. It’s the best option when your process is a commodity function, like HR payroll, where a market solution is a better fit than custom software.
The most common mistake is applying one pattern to every workload. A high-volume, stable financial ledger process demands a different approach than a flexible marketing analytics job. Map the workload’s characteristics to the pattern’s strengths.
Mainframe Batch Modernization Pattern Decision Matrix
To move from intuition to an evidence-based decision, evaluate each pattern against your workload’s specific technical needs and business drivers. This matrix provides the framework for that analysis.
First, classify your batch application: How critical is it? How complex is the code? How much change will it require in the future?
| Pattern | Primary Goal | Typical Cost | Risk Level | Timeline | Best For |
|---|---|---|---|---|---|
| Rehost | Speed and cost reduction | Low | Low | 3-9 Months | Non-critical, stable apps with no planned functional changes. The goal is to exit the data center quickly. |
| Replatform | Cloud optimization | Low-Medium | Low-Medium | 6-18 Months | Apps that can benefit from cloud-native database or storage services without a full rewrite of business logic. |
| Refactor | Preserving business logic while modernizing the tech stack | Medium | Medium | 12-24 Months | Complex, business-critical apps where the embedded logic is valuable and accurate, but the underlying COBOL/JCL is a liability. |
| Rearchitect | Business agility and scalability | High | High | 24+ Months | Monolithic applications that constrain business change and need to be broken down into microservices for real-time or event-driven use cases. |
| Replace | Adopting industry best practices | High | Medium-High | 18-36 Months | Generic functions (e.g., HR, some finance) where a SaaS solution offers superior functionality and eliminates maintenance burdens. |
Using a framework like this transforms your decision-making from guesswork to structured evaluation.
For instance, a mission-critical payment processing job with complex, validated logic is a textbook candidate for Refactoring. In contrast, an end-of-day reporting job that is not time-sensitive and has no new features on the roadmap is a perfect fit for a simple Rehost.
This analysis is the bedrock of any successful legacy system modernization strategy, ensuring your technical approach is directly tied to business outcomes.
Navigating the Technical Minefield of Batch Modernization
Standard cloud migration playbooks fail spectacularly when applied to mainframe batch processing. A staggering 67% of mainframe migration projects fail, not from lack of effort, but from underestimating the unique technical complexities. These projects don’t just go over budget; they often collapse when a seemingly minor detail proves to be a catastrophic, show-stopping problem.
Successfully modernizing your batch environment means navigating a technical minefield where every step matters. Generic advice is useless. You need to know the specific, non-obvious traps that have sunk countless other projects.
Precision Loss in Data Conversion
One of the most dangerous and frequently overlooked issues is data type mismatch, specifically with packed decimals. Mainframes use COMP-3 (packed decimal) fields to store financial data with absolute precision. This is a foundational element of banking, insurance, and retail systems.
When you refactor that COBOL to Java or C#, a naive conversion often maps these packed decimals to standard floating-point data types like float or double. This is a project-killing error. Floating-point numbers are approximations, and this translation introduces minuscule rounding errors that compound with every calculation.
Imagine a payment processing system where every transaction is off by a fraction of a cent. Across millions of transactions, these rounding errors snowball into a financial reconciliation disaster, destroying data integrity and trust in the modernized system. This single issue has caused multiple high-profile modernization failures.
Mitigating this requires a strict data mapping strategy. Your teams must enforce the use of high-precision types like Java’s BigDecimal for any field that was originally COMP-3. This is a day-one rule for preserving financial integrity.
Replicating Complex Job Scheduling
Mainframe batch operations are not a simple collection of scripts. They are highly orchestrated workflows managed by sophisticated schedulers like Zeke, CA-7, or Control-M. These schedulers handle thousands of jobs with intricate dependencies, conditional triggers, and resource rules built up over decades.
Lifting and shifting these jobs to the cloud without a concrete plan for orchestration is a recipe for chaos. The challenge isn’t just running the jobs; it’s recreating the entire dependency graph and control logic in a modern, distributed environment.
- Dependency Mapping: You must meticulously document every predecessor, successor, and conditional relationship for all batch jobs. A job that generates a report cannot run until the data aggregation job it depends on has completed successfully. This is non-negotiable.
- Modern Equivalents: You need to translate mainframe scheduling logic into a cloud-native equivalent like AWS Step Functions, Azure Logic Apps, or platforms like Airflow to build state machines and DAGs (Directed Acyclic Graphs) that replicate the original job flows.
- Failure and Restart Logic: Mainframe schedulers have robust, battle-tested capabilities for handling job failures, including automated restarts from specific checkpoints. This transactional integrity must be painstakingly re-engineered in the cloud to prevent partial data updates or corrupted files.
This decision tree shows how to approach modernization based on the complexity of your batch environment.
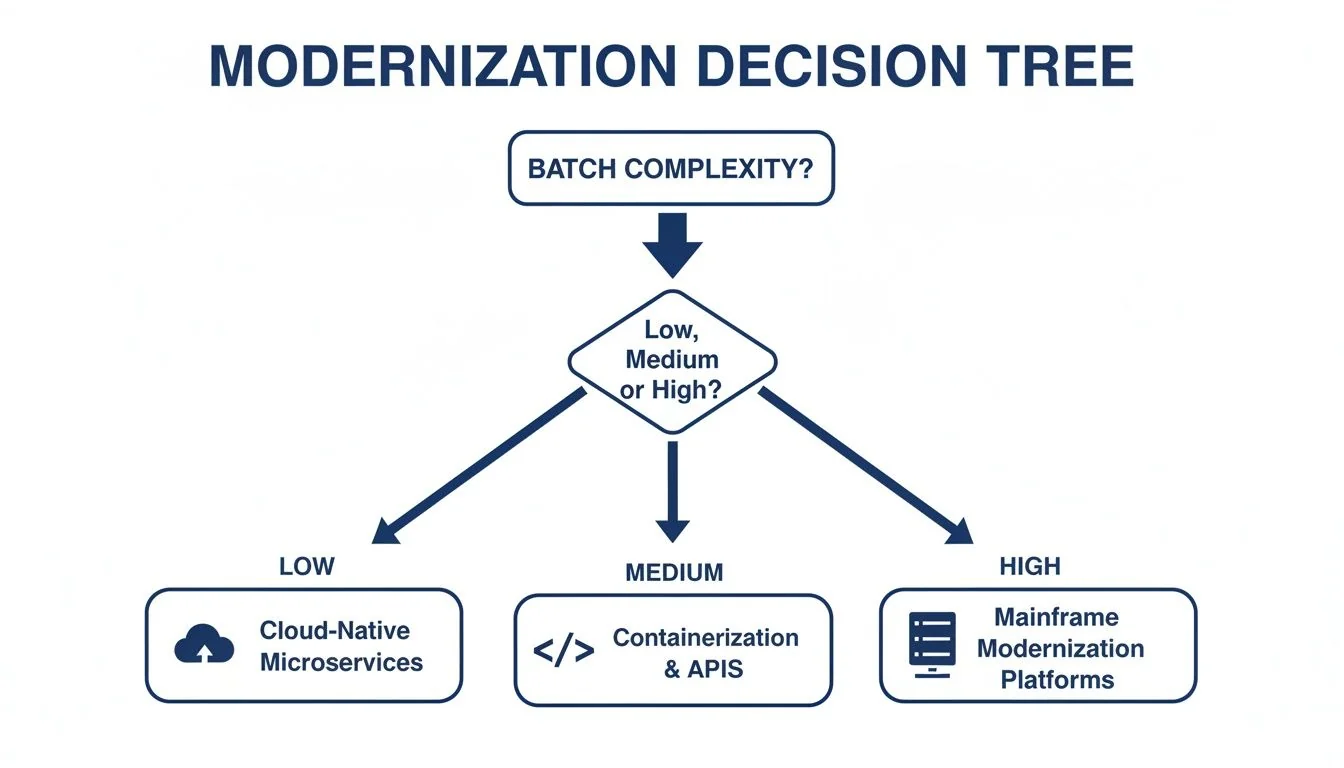
As the chart shows, as batch complexity increases, the right path shifts from simple cloud migration toward more involved code-level work or on-platform modernization.
Handling Stateful Processes and Data
Many mainframe batch jobs are inherently stateful. They rely on the persistence of data across multiple steps within a job or between different jobs in a sequence. A classic pattern is reading a large VSAM file, performing a series of updates, and writing the results back, with the expectation that data state is maintained throughout.
This model directly conflicts with the stateless, ephemeral nature of many modern cloud architectures, like serverless functions. A function might process one record and then disappear, taking any in-memory state with it.
To solve this, you must explicitly manage state using external services:
- Externalize State: Use a cloud database (like Amazon DynamoDB or Azure Cosmos DB) or an in-memory data store (like Redis) to hold state between process steps. State cannot live in the application’s memory.
- Idempotency: Design your new services to be idempotent. This means they can run multiple times with the same input and produce the exact same result. This is critical for building reliable restart capabilities in a distributed system.
Ignoring the stateful nature of batch processing is a common mistake that leads to unreliable and un-debuggable systems. Each of these technical pitfalls represents a significant risk to your mainframe batch processing modernization project. Addressing them proactively during planning and design is the only way to ensure a successful outcome.
When to Modernize On-Platform Instead of Migrating
The relentless “cloud-first” mantra often drowns out a critical reality: not every mainframe workload belongs in the cloud. Pushing everything to the cloud is a dangerous oversimplification. For many high-volume, mission-critical batch processes, the smartest move is to modernize on the mainframe itself.
This isn’t resisting change. It’s making a disciplined, evidence-based decision. Data shows that’s exactly what your peers are doing. Batch modernization is not a rip-and-replace effort. Only 3.2% of mainframe users plan a full decommissioning in the next three years. Meanwhile, 34% are committed to the latest z/OS release and 40% to the prior one, all to protect the stable, high-throughput performance their businesses depend on.
You can discover more insights from the 2026 Arcati Mainframe User Survey to see why this cautious approach is so common, especially when you consider that mainframes still power over 50% of revenue workloads at 67% of large enterprises.
Identifying Candidates for On-Platform Modernization
Deciding to modernize in place comes down to a clear-eyed assessment of the workload. Migrating a batch system that already crushes its SLAs with unmatched reliability introduces massive risk for questionable gain.
The best candidates for on-platform modernization share these traits:
- Extreme Performance Requirements: These are jobs that process mountains of data within tight, non-negotiable windows. Think core banking ledgers or end-of-day insurance claims processing, where the mainframe’s raw I/O and processing power are the right tool for the job.
- High Business Criticality with Low Volatility: These are foundational business systems whose logic is stable and well-understood. The risk of breaking these “crown jewel” applications during a migration far outweighs the theoretical benefits of a rewrite.
- Deep Integration with Other Mainframe Assets: These are workloads tightly woven into your mainframe ecosystem—DB2, IMS, VSAM, and other batch jobs. Untangling these dependencies for a migration often turns into a costly project with a deeply negative ROI.
On-Platform Modernization Techniques
Modernizing on the mainframe does not mean you’re stuck with 30-year-old COBOL practices. Today’s zSystems have powerful tools that let you integrate modern development and deployment patterns alongside legacy batch jobs.
The goal isn’t to preserve the mainframe as a museum piece. It’s to evolve it into a hybrid platform that plays to its strengths while exposing its capabilities in a modern way. You get the rock-solid reliability of the mainframe with the agility of the cloud.
Key techniques that work include:
- Containerization with z/OS Container Extensions (zCX): This is a game-changer. It lets you run standard Linux-based Docker containers directly on z/OS. You can deploy a new microservice written in Python or Java right next to your COBOL batch job, allowing them to communicate at memory speed with zero network latency.
- API Enablement with z/OS Connect: Instead of attempting a risky migration of a complex batch function, you can wrap it and expose its logic as a secure RESTful API. This lets your modern, cloud-native apps invoke mainframe transactions and access data without needing to know what COBOL or CICS is doing under the hood.
- AI-Powered Performance Tuning: Modern monitoring tools use machine learning to analyze workload performance, pinpoint bottlenecks, and proactively suggest optimizations. This is about sweating the asset—getting more throughput from existing hardware, driving down MIPS consumption, and deferring expensive upgrades.
Choosing to modernize on-platform is a strategic move to maximize the value of what you already own while surgically reducing risk. This balanced perspective is the core of any successful mainframe modernization strategy that delivers real business outcomes.
Validating Success with a Parallel Run Framework
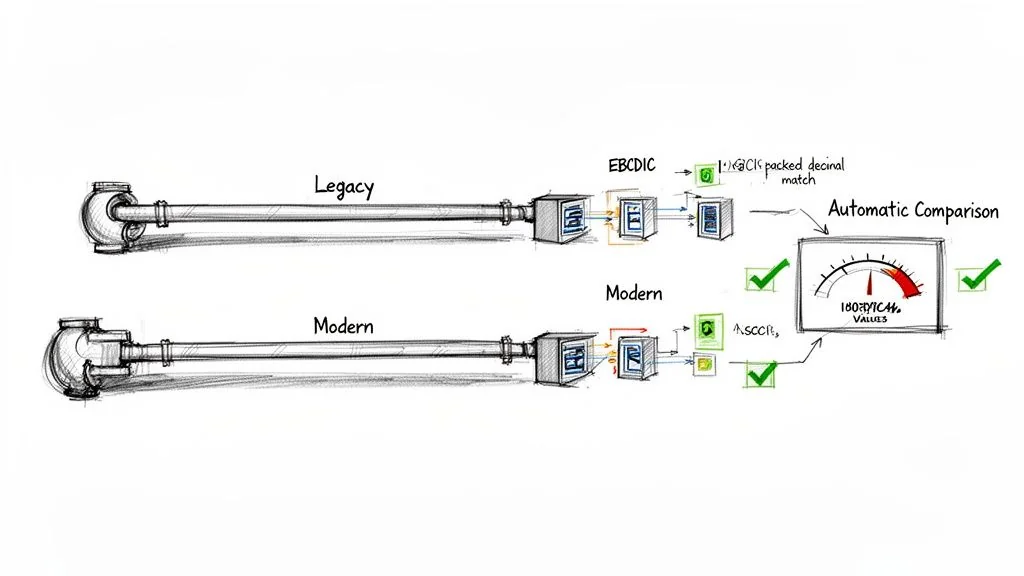
When modernizing mainframe batch, one principle matters: the new system must produce results that are bit-for-bit identical to the old one. There is no room for “almost right.” This is where a parallel run validation framework becomes the single most critical part of your entire project, far surpassing standard unit or integration tests.
Parallel running is not just having two systems on at the same time. It’s an automated, at-scale comparison of every output file, database record, and report generated by both your legacy mainframe and the new cloud-native system, using the exact same production input data. The goal is to prove 100% functional equivalence under real-world pressure before a single user touches the new system.
Executing a Parallel Run at Scale
A successful parallel run is a disciplined, multi-step dress rehearsal for your go-live. A single failed run invalidates the process and sends the team back to find the bug, but a successful one builds the concrete evidence needed for a non-event cutover.
The heart of this framework is automation. Manually comparing millions of records across terabyte-sized files is not just impractical; it’s impossible. You must build or buy tooling to handle the massive volume and complexity of this task.
A parallel run is the ultimate source of truth. It bypasses debates about code quality or architectural purity and answers the only question the business cares about: “Does it produce the exact same results?” Any deviation, no matter how small, is a P1 bug.
This process is designed to expose subtle issues that unit tests always miss, like compounding rounding errors from mishandled COMP-3 data or tiny differences in sorting logic between EBCDIC and ASCII environments.
The Parallel Run Validation Checklist
Use this checklist to structure your execution. Skipping a single step introduces unacceptable risk.
-
Synchronize Production Data:
- Take a clean snapshot of all relevant production data from the mainframe (DB2, VSAM files, etc.) at a precise point in time.
- Load this identical dataset into your target cloud environment (e.g., PostgreSQL, Amazon DynamoDB). This ensures both systems start from the exact same state.
-
Execute Both Systems Simultaneously:
- Feed the identical input files and transaction data for a full batch cycle (e.g., a complete 24-hour business day) to both the legacy mainframe and the new modernized system.
- Capture everything they produce: flat files, database states after the run, generated reports, and all outbound data feeds.
-
Automate the Comparison:
- Use specialized comparison tools to perform a delta check between the legacy and new system outputs.
- This tool must be intelligent enough to handle format differences (EBCDIC vs. ASCII, COMP-3 vs. BigDecimal) to compare the logical data, not just raw bytes.
- The tool must flag every discrepancy—down to the last decimal place—and generate clear reports pinpointing where the divergence occurred.
-
Analyze and Remediate Discrepancies:
- Treat every difference as a high-priority bug. A dedicated team of developers and SMEs must perform root cause analysis, whether it’s a code flaw, data type mismatch, or an environment configuration error.
- After implementing a fix, you must restart the entire parallel run from the beginning. You cannot simply test the fix in isolation; the goal is to validate the entire system.
-
Achieve a “Golden” Run:
- Repeat this cycle of running, comparing, and fixing until you achieve a “golden” run—a complete, end-to-end execution with zero discrepancies.
- Only after you have a verified golden run can you confidently schedule your cutover.
This rigorous framework is the only proven method to de-risk a mainframe batch processing modernization and guarantee business continuity. It replaces hope with hard evidence.
Your Actionable Modernization Roadmap
Turning a modernization idea into a funded project is where most initiatives die. This is a concrete, step-by-step plan to get your mainframe batch modernization off the ground and build momentum.
Each step is designed to de-risk the project and connect technical execution directly to business outcomes.
Step 1: Inventory and Classify Your Workloads
Your first move is a full inventory of every batch workload. Do not treat all jobs as equal. Classify them on two axes: business value and technical complexity.
-
Business Value: How critical is this job? Does it drive revenue, enable core operations, or satisfy a regulator? High-value jobs are your pilot candidates.
-
Technical Complexity: How entangled is this job in the mainframe ecosystem? Is it a web of dependencies, or is it relatively self-contained?
This creates a quadrant map. You are looking for the sweet spot: the high-value, low-complexity workloads. These offer a quick, meaningful win with manageable risk.
Step 2: Build a Preliminary Business Case
With a target workload identified, build a preliminary business case. The Banking and Financial Services (BFSI) sector is driving this market at an 8.9% CAGR, but don’t let that suggest it’s easy.
A staggering 67% failure rate for these projects is common due to batch-specific traps like losing transaction integrity during migration. Start with industry benchmarks, which often cite costs between $1.50 and $4.00 per line of code (LOC) for refactoring. Then, adjust those numbers based on the complexity of your chosen workload.
The goal is not a perfect number; it’s a defensible one. To sharpen your financial models, read the full research on mainframe modernization market trends.
Step 3: Socialize the Why with Stakeholders
Armed with a target and a preliminary budget, sell the why. Stop talking about MIPS, COBOL, or technical debt. Business leaders do not care.
Focus the conversation on two things: agility and risk reduction. Frame the project as a way to launch new products faster and eliminate the existential threat of a retiring workforce and brittle, unchangeable systems. This shifts the perception from a legacy cost center to a strategic business enabler.
Step 4: Initiate a Targeted Proof of Concept
Execute. Pick one high-value, low-risk batch application from your map and launch a targeted Proof of Concept (PoC). The goal is not to migrate the whole thing.
The PoC has one job: validate your chosen modernization pattern and smoke out the hidden technical landmines before they derail a multi-million dollar project.
This small-scale effort provides priceless, real-world data to refine your cost models, timelines, and technical approach. It transforms your plan from an aspiration into a battle-tested strategy, ready for an enterprise-wide rollout.
Tough Questions From The Trenches
Actionable answers to the hard questions technical leaders ask about mainframe batch modernization. No fluff, just field-tested reality.
What Is the Most Common Reason Mainframe Batch Modernization Projects Fail?
The single biggest reason projects fail—a trap that snares up to 67% of them—is a profound underestimation of the batch-specific technical debt. Teams fixate on COBOL-to-Java code conversion and miss the real killers.
These are the subtle, system-breaking details: silent data corruption from EBCDIC-to-ASCII character set mismatches, catastrophic financial miscalculations from floating-point errors when converting COMP-3 packed-decimal fields, and the nightmare of reverse-engineering decades of dependencies baked into a scheduler like CA-7.
Without specialists who have deep, hands-on experience in both the mainframe and the target cloud environment, these issues lead to corrupted data, blown SLAs, and total project collapse.
Can AI Genuinely Accelerate COBOL to Java Refactoring?
Yes, but it’s a tool, not a silver bullet. AI-driven refactoring tools are effective at the initial, brute-force conversion. They can parse complex COBOL, JCL, and copybooks, slashing the manual code translation effort by 40-70%.
But make no mistake: expert human oversight is absolutely non-negotiable. AI is an accelerator, not a magic button. You still need your best engineers to resolve logical ambiguities the AI misses, break up monolithic spaghetti code into sensible microservices, and design a rigorous testing strategy to prove the new code is functionally identical to the old.
Think of it as a powerful junior developer that does the first pass, but a senior architect must still approve the pull request.
When Does It Make Sense Not to Modernize a Batch Process?
Modernization is not a religion. Sometimes, the smartest decision is to leave a process exactly where it is. Pull the plug on a modernization plan if the batch process fits any of these profiles:
- Low Business Impact: The process is stable, runs without issue, has low transaction volume, and offers zero strategic advantage if moved. The ROI is almost certainly negative.
- Scheduled for Decommissioning: The entire application or business function it serves is already on a formal roadmap to be replaced or retired. Modernizing a component of a dying system is burning money.
- Extreme, Optimized Performance: The job has unique I/O or processing demands that are perfectly, and often cheaply, met by the mainframe’s architecture. If there is no compelling business driver for change, you risk trading a stable, high-performance process for a costly and underperforming cloud equivalent.
In these scenarios, sticking with on-platform maintenance is not a failure—it’s a fiscally responsible engineering decision.