
Building a Real-Time Data Pipeline Architecture That Doesn't Collapse
Your legacy batch ETL pipelines are a direct liability, preventing the deployment of modern, AI-driven applications. The ‘store-then-analyze’ model, built for historical reporting, introduces fatal data latency that makes real-time fraud detection, dynamic pricing, or responsive supply chains impossible. Data that is hours old is operationally worthless for immediate decisions.
This isn’t a performance issue; it’s an architectural failure. Batch jobs create engineered data downtime. A pipeline failure discovered hours late means your dashboards and AI models operate on stale, untrustworthy data, capping your business’s ability to respond and introducing significant operational risk. Migrating from batch to real-time collapses data latency from hours to milliseconds, but it requires a fundamental architectural shift, not just faster batch jobs.
Why Your Batch ETL Is a Modernization Bottleneck
Modernization is not about speeding up batch jobs. It is about abandoning the batch model for a paradigm of continuous intelligence. The value of data decays rapidly; a real-time data pipeline architecture ensures data is processed and actionable the moment it is generated. This is the price of admission for competitive operational agility.
- Operational Agility: Real-time pipelines enable immediate response. A fraudulent transaction is blocked in milliseconds, not discovered hours later after the money is gone.
- Enhanced Customer Experience: Systems react to user behavior instantly, offering relevant recommendations or proactive support without perceptible delay.
- AI and ML Efficacy: Machine learning models trained on real-time data streams produce far more accurate and timely predictions. A model using day-old data is always a step behind reality.
The fragility of legacy systems is clear: 32.3% of organizations take hours just to become aware of data pipeline problems. By 2026, real-time data access will be mandatory for AI-enabled applications, as batch pipelines fail to meet the freshness requirements for operational decision-making.
Before committing to modernizing your data platform, the trade-offs between sticking with batch processing and migrating to a real-time architecture must be clear. This matrix outlines the key differences that directly impact business outcomes.
Batch vs. Real-Time Pipeline Decision Matrix
| Attribute | Batch Architecture (Legacy) | Real-Time Architecture (Modern) |
|---|---|---|
| Data Latency | Hours to days | Milliseconds to seconds |
| Business Use Cases | Historical reporting, BI dashboards | Fraud detection, personalization, IoT monitoring, dynamic pricing |
| Decision-Making | Strategic (long-term trends) | Tactical & Operational (immediate action) |
| Failure Impact | High. Hours of data loss or reprocessing required. | Low. Recovery from last checkpoint, minimal data loss. |
| Infrastructure Cost | Lower compute cost (runs periodically) | Higher compute cost (always on) |
| Complexity | Simpler logic, complex orchestration | Complex state management, simpler orchestration |
This comparison clarifies that while batch processing has a role for non-urgent tasks, it is a significant liability for any modern application dependent on fresh data to drive value.
Assessing Your Architectural Debt
Answering “yes” to any of the following questions indicates you are accumulating architectural debt that will choke future growth:
- High Data Latency: Does it take hours for operational data to reach your analytics and AI models?
- Slow Incident Response: When a supply chain disruption occurs, are your teams forced to react using outdated data?
- Inability to Support New Use Cases: Are you unable to build features like live inventory tracking or instant personalization because your data platform cannot handle them?
Answering these questions is the first step toward a successful data modernization initiative. Moving from batch to real-time is a strategic decision to build a more responsive organization.
Anatomy of a Modern Real-Time Pipeline
A real-time data pipeline is not a simple pipe; it is a high-performance system where every component must execute its job with millisecond precision. A failure in any one stage turns the promise of sub-second data into another broken SLA.
This diagram shows the fundamental chasm between yesterday’s batch ETL and today’s always-on, real-time intelligence.
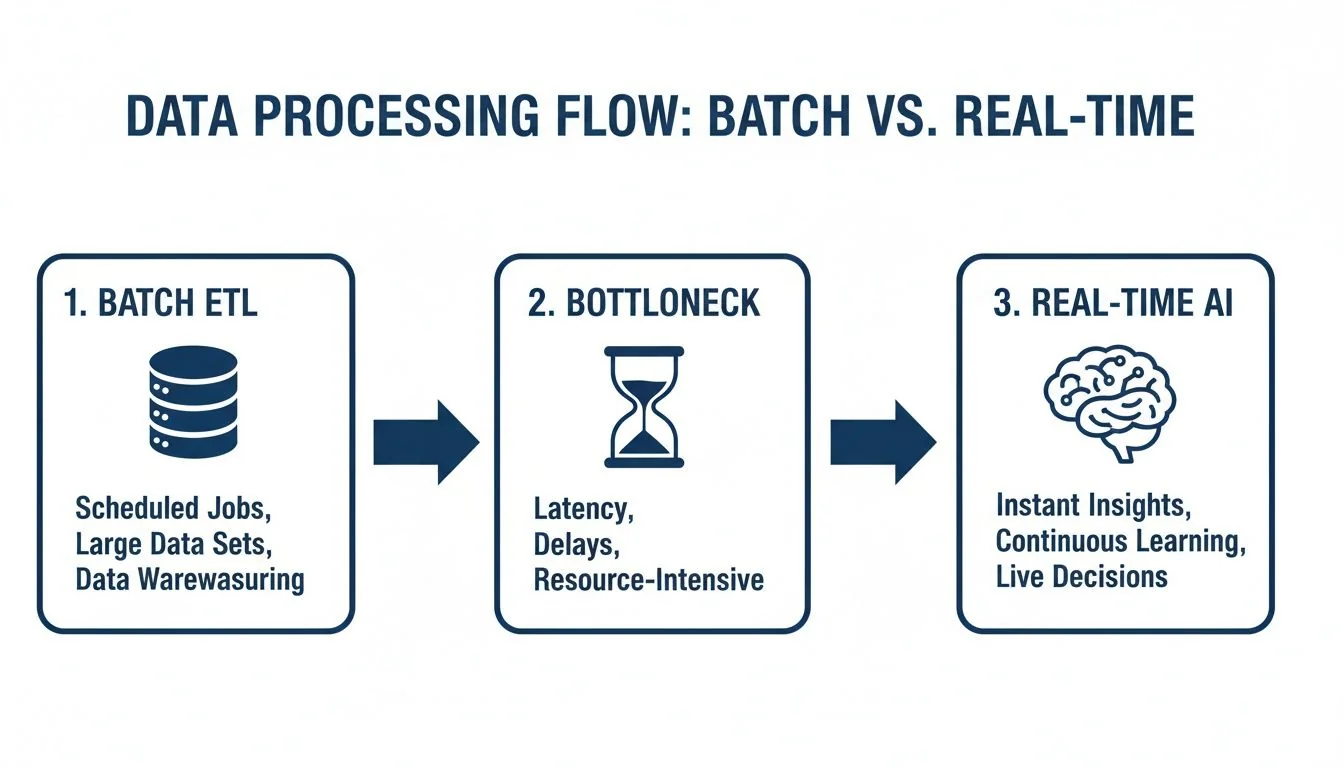
Batch systems are an engineered bottleneck. They force you to wait. A proper real-time architecture feeds AI and applications directly, turning data into action the moment it’s generated. The following components are critical for delivering on this promise.
Stream Ingestion and Messaging
This is the “first mile” where data freshness is won or lost. The goal is to capture events from sources like application logs, IoT sensors, or database change streams instantly. For unstructured sources, AI-powered data extraction engines impose order at the entry point.
Captured events are handed off to an event streaming platform. This is the central nervous system of your architecture, decoupling producers from consumers and acting as a durable, high-throughput shock absorber that prevents data loss when downstream services fail.
- Ingestion Tools: Kafka Connect or Fluentd act as reliable collectors, funneling data into the pipeline.
- Messaging Platforms: Apache Kafka is the industry standard for throughput and fault tolerance. Apache Pulsar is a strong alternative, offering built-in multi-tenancy and tiered storage.
The trade-off is control versus cost. Self-hosting Kafka provides ultimate control but brings significant operational overhead. Managed services like Confluent Cloud eliminate this overhead for a premium.
Stream Processing
Raw data is fast but not intelligent. A stream processing engine pulls events from the messaging platform and applies logic on the fly—enriching data, calculating fraud scores, or aggregating metrics.
The stream processor is the active brain of your pipeline. It’s the difference between simply moving data quickly and deriving intelligence from it in the moment.
Your choice of engine dictates the pipeline’s latency and power. Apache Flink is purpose-built for stateful, low-latency processing and is the standard for use cases demanding exactly-once processing guarantees. Spark Streaming operates on micro-batches, resulting in slightly higher latency but often better throughput for tasks that can tolerate it.
Real-Time Datastore and Serving Layer
Processed data requires a home, but a traditional data warehouse is the wrong address. Warehouses are built for large-scale, batch-oriented queries and will choke on the rapid-fire, low-latency lookups that real-time applications demand.
This is the job of a real-time datastore, engineered to absorb a constant firehose of incoming data and serve queries in sub-second time.
| Datastore Type | Key Characteristics | Common Use Cases | Example Tools |
|---|---|---|---|
| In-Memory | Extreme low latency, volatile storage | Caching, session stores, leaderboards | Redis, Hazelcast |
| Columnar Analytics | High-throughput ingestion, fast analytical queries | Real-time dashboards, operational monitoring | Apache Druid, ClickHouse, Apache Pinot |
| Search-Based | Powerful text search and aggregations | Log analytics, application performance monitoring (APM) | Elasticsearch, OpenSearch |
This final layer serves the processed data to a live dashboard, microservice, or alerting system. When these three components work in concert, they form a resilient, high-performance architecture that can power a modern, data-driven business.
Choosing Your Architectural Pattern: Lambda vs. Kappa
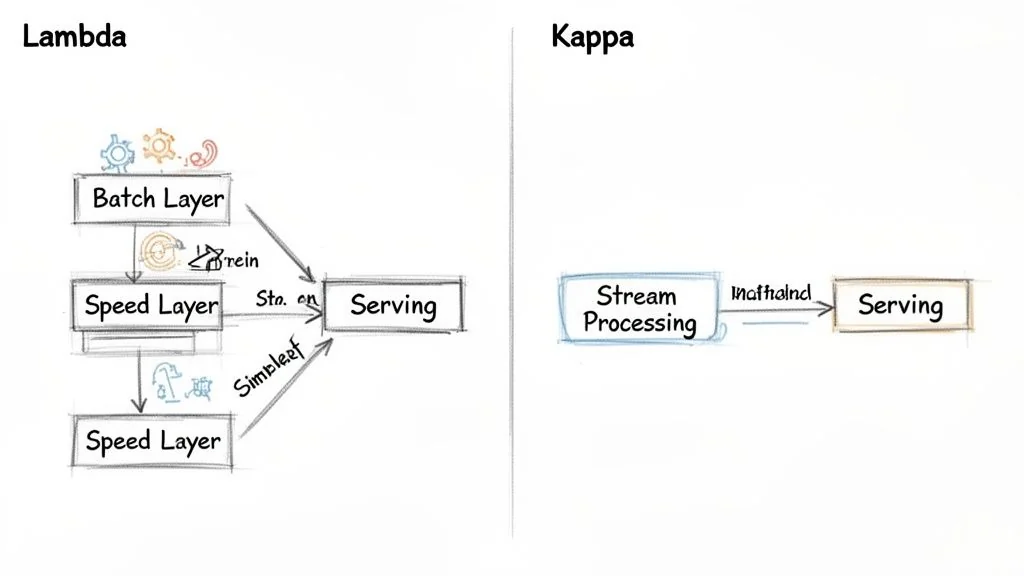
The choice between Lambda and Kappa is a foundational decision that locks in operational costs and engineering complexity for years. Get this wrong, and you commit your team to chasing data discrepancies between two systems that should have been one.
The Lambda architecture was a necessary compromise when stream processing was immature. It delivers both fast, real-time views and comprehensive batch views by running two separate data paths in parallel. This dual-path system is a sign of technical debt, forcing engineers to build and maintain two sets of logic—one for the “speed layer” (streaming) and another for the “batch layer.” This duplication is a massive tax on productivity and a primary cause of bugs where real-time dashboards and quarterly reports disagree.
The Case for Kappa Architecture
The Kappa architecture eliminates this duality. Its core principle is to use a single, unified stream processing engine for everything. Real-time dashboards, historical reprocessing, and batch-style analytics all run through one pipeline. This is enabled by mature tools like Apache Flink and immutable event logs like Apache Kafka.
In a Kappa architecture, your streaming system is your batch system. There is no batch layer. Reprocessing historical data simply means replaying events from your durable message queue through the same stream processing logic.
For any new real-time data pipeline architecture, this unified model slashes complexity by eliminating the second codebase. Maintenance becomes easier, and the risk of real-time and batch views drifting apart is removed. For most new projects, Kappa is the correct choice.
When Lambda Still Makes Sense
Despite Kappa’s superiority, Lambda remains a pragmatic choice when constrained by legacy systems or existing team skills.
- Existing Batch Infrastructure: If your company depends on a massive data lake or warehouse with years of battle-hardened batch ETL, a “rip-and-replace” is not feasible. Lambda allows you to add a real-time speed layer without disrupting the existing batch ecosystem.
- Team Skill Set Mismatch: If your data team is composed of SQL experts skilled in tools like dbt but lacks deep stream processing expertise, Lambda provides a smoother on-ramp. They can continue using SQL for the batch layer while a smaller team builds out the streaming path.
This is relevant for modernization projects replacing legacy ETL with an ELT approach, often using dbt for SQL-based transformations in a lakehouse. This can cut transformation overhead and helps unify batch and streaming on platforms like Delta Lake. This strategy, as detailed in an article on real-time data processing, bridges the gap between traditional workflows and modern streaming.
Change Data Capture as a Modernization Catalyst
Change Data Capture (CDC) is a powerful pattern for enabling a real-time architecture. CDC tools like Debezium tap into the transaction logs of legacy databases (e.g., Oracle, PostgreSQL) and stream every INSERT, UPDATE, and DELETE as an event into your message queue.
This turns a monolithic database from a data silo into a live event source without modifying the legacy application’s code. It is a non-invasive, high-impact first step for any enterprise modernization effort, feeding directly into either a Lambda or Kappa architecture. The choice then depends on whether you process this CDC stream alongside an existing batch system (Lambda) or make it the single source of truth for a new, unified pipeline (Kappa).
Achieving Operational Excellence in Real-Time Systems
A real-time data pipeline in production is a chaotic system that demands relentless discipline to deliver its low-latency promise. A pipeline is only as valuable as it is trustworthy. Without operational excellence, you are just building a faster way to generate bad data. This is not about just keeping the lights on; it’s about building a system that anticipates and survives the failures inherent in distributed computing.
Building for Fault Tolerance
Fault tolerance is the bedrock of any production-ready real-time system. You must design with the assumption that components will fail, networks will partition, and load will spike.
A critical strategy is stateful checkpointing. Stream processing engines like Apache Flink periodically save their internal state (e.g., windowed aggregations) to durable storage. If a job fails, it restarts from the last successful checkpoint, preventing data loss and minimizing reprocessing time.
Managing backpressure is also non-negotiable. When a downstream system cannot keep up, a well-designed pipeline automatically slows down data ingestion at the source to prevent overwhelming the slower component and causing cascading failures.
The goal is to achieve exactly-once processing semantics. This guarantees that every event is processed once and only once, even with failures and retries. It eliminates both data loss and data duplication, which is mission-critical for financial transactions or any system where accuracy is absolute.
The Observability Mandate
You cannot manage what you cannot measure. For a real-time pipeline, observability extends beyond CPU and memory to metrics that map directly to the health and performance of the data flow. Ignoring this leads to “silent failures”—where the pipeline appears healthy but is delivering stale or incomplete data for hours.
This focus on operational resilience is a core principle of good system design. Thinking about AI Architecture for Longevity from day one ensures your pipelines are not just fast but also manageable for years. Our guide on DevOps integration modernization offers a deeper dive into the tools and processes needed to build a robust observability stack.
The following checklist is a starting point for assessing the operational readiness of your pipeline. These are the vital signs of your system.
Real-Time Pipeline Observability Checklist
| Metric Category | Key Metrics to Track | Acceptable Thresholds | Tooling Examples |
|---|---|---|---|
| Data Freshness | End-to-End Latency | <1 second for critical paths | OpenTelemetry, custom timestamps |
| Throughput | Events Processed Per Second | Varies by use case; watch for sudden drops | Prometheus, Grafana, Datadog |
| Consumer Health | Consumer Lag (e.g., Kafka Lag) | <1000 messages; should not grow over time | Burrow, Kafka-specific monitoring tools |
| System Correctness | Watermark Gaps, Late Events | Monitor count of late-arriving data | Flink/Spark UI, custom metrics |
| Schema Integrity | Schema Drift Alerts | Zero unexpected changes | Confluent Schema Registry, Apicurio |
| Resource Usage | Backpressure Events, Checkpoint Failures | Zero sustained backpressure; <1% failure rate | Flink Dashboard, Prometheus alerts |
This checklist is a core part of your design and testing phases. If you cannot measure these metrics, you do not have a production-ready system.
Your Phased Modernization Roadmap
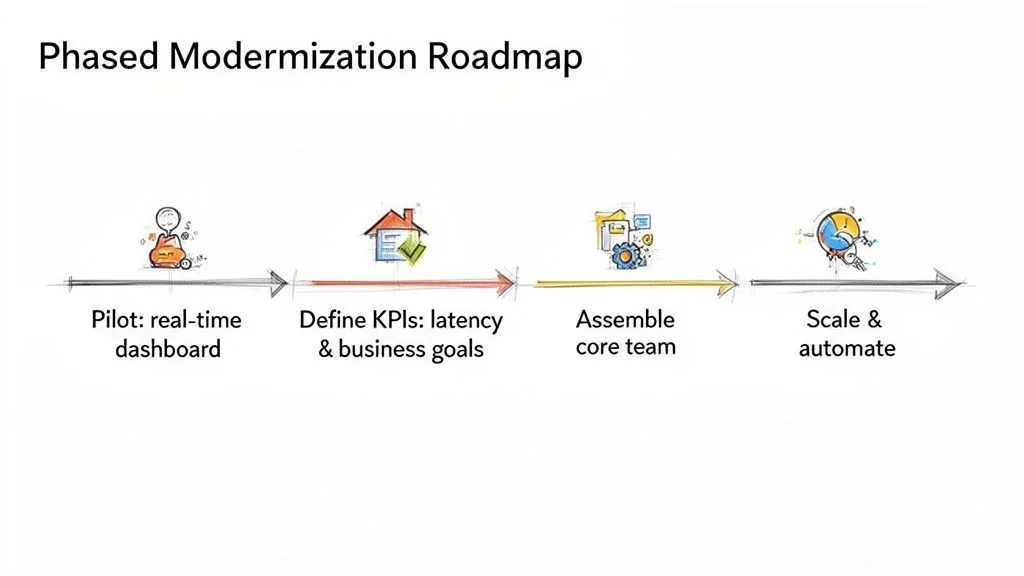
Theoretical discussions of real-time data pipeline architecture are worthless without a concrete execution plan. Avoid a “big bang” migration; this approach is a recipe for budget overruns and project failure. A phased approach builds momentum and de-risks the transformation.
Step 1: Secure a High-Impact Pilot Project
Your first move is to identify a high-impact, low-risk pilot project. This is your beachhead to prove the value of real-time data to skeptical stakeholders.
Good candidates for a pilot are self-contained and deliver obvious value:
- A real-time dashboard for a critical function like order fulfillment.
- An MVP fraud detection system that flags transactions for manual review.
- A live inventory tracking system for one high-value product line.
Step 2: Define and Measure Success with KPIs
Once you have a pilot, define success with ruthless clarity. Key performance indicators (KPIs) must be measurable and tied directly to a business outcome.
Success metrics must be specific and unforgiving. Aim for targets like “reduce fraud-related losses by 15% within Q3 by cutting detection latency from 10 minutes to under 500 milliseconds.” This forces a direct link between technical execution and financial impact.
These metrics become the north star for the project, justifying the investment and guiding architectural trade-offs.
Step 3: Assemble Your Core Team and Select Partners
With a defined project and clear goals, assemble a small, dedicated team with a mix of skills: data engineers with streaming expertise (e.g., Flink or Kafka Streams), backend developers, and a product owner who understands the business problem.
The implementation best practices are non-negotiable: asynchronous communication, idempotent consumers, and robust state management for late-arriving data. This discipline is how you avoid the astronomical 67% failure rate seen in ungoverned data projects. You can find more best practices for data integration on Domo.com.
Step 4: Make the Build vs. Buy Decision
The next make-or-break decision is whether to build a custom platform or buy a managed service. This is a strategic choice that dictates your team’s focus and long-term operational burden. The “build” route offers total control but comes with a project failure rate that exceeds 50% due to the complexity of running stateful, distributed systems like Kafka and Flink at production scale.
The decision to build a real-time platform from scratch is effectively a decision to become a data infrastructure company. If that is not your core business, you are likely better off buying.
Use this framework to guide the decision. A “buy” decision is strongly indicated if you answer “yes” to more than two of these questions:
- Speed to Market: Is a solution in under three months more valuable than total infrastructure control?
- Core Competency: Is your engineering team’s mission to build customer products, not manage data plumbing?
- Talent Scarcity: Do you lack senior-level, in-house experts with deep knowledge of streaming technologies?
- Operational Overhead: Do you want to avoid the 24/7 pager duty of managing a complex distributed system?
Managed services like Confluent Cloud, Decodable, or Tinybird allow your team to focus on business logic, not infrastructure. This path trades some control for a massive reduction in risk, faster implementation, and a predictable cost model. Recent data shows that organizations adopting cloud-native architectures for their data pipelines are seeing a 3.7× ROI from performance boosts and fewer production incidents. Tools like streaming warehouses—Snowpipe and BigQuery Streaming—and SQL streaming platforms like ksqlDB are key drivers of this return. You can find more data behind these real-time processing findings on Tinybird.co.
Next Steps: Address Your Immediate Technical Hurdles
Theory is clean; production is messy. Here are answers to the operational questions that arise after launch, addressing problems that separate a pipeline that merely works from one that is resilient and manageable.
How Do You Handle Schema Evolution in a Live Pipeline?
Changing a data schema mid-flight without breaking consumers is a primary challenge. The only reliable method is a centralized schema registry, like those from Confluent or Apicurio. It acts as the single source of truth for your data’s structure.
When a producer attempts to send a message with a new schema, it is first validated against the registry. This is where you enforce compatibility rules, and BACKWARD compatibility is the standard for preventing production failures.
- Backward Compatibility: Your safety net. It guarantees that downstream consumers built for the old schema will not crash when they encounter data written with the new one. This typically means you can only add new optional fields or delete fields that were already optional.
- Forward Compatibility: The reverse. It allows consumers running newer code to process data produced with an older schema.
- Full Compatibility: The schema is both backward and forward compatible, which is often overkill.
Enforcing these rules programmatically stops “poison pill” messages at the source, allowing you to evolve schemas with zero downtime.
What Is the Best Strategy for Reprocessing Historical Data?
Sooner or later, you will update business logic and need to re-run it against historical data. In a Kappa architecture, this process is elegant because there is no separate batch layer to manage.
The strategy is simple: treat your historical data as just another stream. Do not touch your live job. Instead, deploy a new, parallel instance of your stream processing application.
Configure this new job to read from the beginning of your event log (e.g., offset 0 in a Kafka topic). It will churn through all historical events using the new logic, writing its corrected output to a new table or topic.
Once this reprocessing job catches up to the live stream, perform an atomic switch, pointing downstream applications to the new, corrected data source. Then, shut down the old job and its output. This is a clean, safe, and repeatable pattern that avoids the nightmare of maintaining two different codebases for batch and streaming.