
Modernizing Legacy Infrastructure: A Guide to IaC Adoption
Trying to bolt Infrastructure as Code onto a legacy system is where most modernization projects die. Deployment error rates skyrocket to between 30-50%, operational costs balloon, and your most critical systems become a source of major business risk. The core idea of IaC—declarative, automated, predictable—runs headfirst into the reality of environments built on a decade of manual tweaks, undocumented dependencies, and tribal knowledge.
The problem isn’t the technology. It’s the friction between IaC principles and the “ClickOps” reality of legacy systems—manual changes in a GUI that are never version-controlled. This is the exact point where infrastructure as code adoption legacy projects stall and fail. You can’t just slap a tool like Terraform or Pulumi on top of chaos and expect order.
The Inevitable Clash: IaC vs. Legacy Reality
Adopting IaC for legacy systems isn’t a “nice-to-have” tech project. It’s a critical business continuity and risk mitigation strategy. That undocumented, manually-configured infrastructure is a massive liability, and the “tribal knowledge” required to run it is your company’s biggest single point of failure.
The Real Cost of Doing Nothing
Kicking the can down the road isn’t a cost-saving move. It’s actively accepting escalating risk. Every manual deployment, every hotfix, every snowflake server is a liability leading to outages and security holes. This reality is why the IaC market is set to explode from USD 2.22 billion in 2026 to USD 12.86 billion by 2032. Organizations are desperately trying to escape the quicksand of manual configuration.
Here’s what that quicksand looks like in practice:
- Senior Engineers as Firefighters: Your best people are not innovating; they’re spending their days troubleshooting configuration drift between a staging environment someone updated by hand and a production environment no one has touched in months.
- Pervasive Security Gaps: Auditing a manually configured system is nearly impossible. You cannot prove compliance with standards like PCI DSS or GDPR, leaving you exposed to massive fines and breaches.
- Innovation at a Standstill: When it takes weeks to spin up a new, production-like environment for development and testing, your product roadmap grinds to a halt.
The operational difference between a manual approach and an IaC-managed one is a step-change in performance and risk.
Legacy vs. IaC-Managed Infrastructure: Operational Metrics
| Metric | Legacy Manual Operations | IaC-Managed Operations |
|---|---|---|
| Change Failure Rate | 15-30% | <5% |
| Mean Time to Recovery (MTTR) | Hours to Days | Minutes |
| Environment Provisioning Time | Days to Weeks | Minutes |
| Security Patch Compliance | 60-70% (at best) | 99%+ (automated) |
| Audit & Compliance Effort | High (manual evidence gathering) | Low (code is the evidence) |
| Engineer Onboarding Time | Months (tribal knowledge) | Days (read the code) |
The data is clear. Manual operations are not just slower; they are fundamentally riskier and more expensive. IaC directly attacks these failure points.
The core challenge is that IaC demands consistency and predictability, while legacy systems are defined by their exceptions and undocumented history. A successful adoption plan must bridge this gap, not ignore it.
Grappling with fragile environments requires a specific playbook. It’s not about boiling the ocean but about making strategic, incremental progress. For proven approaches, see these Legacy System Modernization Strategies That Actually Work. The question is no longer if you should codify your infrastructure, but how.
Brownfield Discovery and Risk Assessment
You cannot codify an infrastructure you don’t fully understand. Before you write a single line of IaC, you must conduct a thorough brownfield discovery. This isn’t just running a script against your CMDB; it’s creating a living map of the undocumented servers, tangled network dependencies, and brittle application connections that exist only in the heads of your senior engineers.
Underestimating this legacy debt consistently inflates project timelines and budgets by 25-35%. Get this wrong, and you’re looking at a series of failed pilots that bleed stakeholder confidence dry.
Uncovering the Undocumented Reality
Your first job is to get past official documentation and uncover the “spaghetti configurations.” Blend automated tooling with structured, targeted interviews.
- Automated Discovery Tools: Use network traffic analyzers and application dependency mapping tools to trace the actual communication paths between servers, databases, and services.
- Targeted Interviews: This is where the real gold is. Sit down with the engineers who live and breathe these systems. Ask them what breaks first during an outage. Ask them which servers they are terrified to reboot.
- Configuration Forensics: Pull configurations directly from devices. Go through firewall rules, load balancer settings, and application config files looking for hardcoded IP addresses and implicit, fragile dependencies.
You’re mapping reality, not just validating an out-of-date Visio diagram. Our guide on legacy system modernization offers practical frameworks for deconstructing these systems.
The Legacy Risk Assessment Matrix
Once you have a map, classify each component with a risk assessment matrix to prioritize your work. This isn’t just about what’s technically possible; it’s about business impact.
The objective is not to codify everything. The objective is to strategically apply IaC where it delivers the most significant reduction in risk and the highest operational leverage. Attempting to boil the ocean is a guaranteed path to failure.
Use a simple scoring system (e.g., 1-5, low to high) for each axis. This generates a clear priority score and shows you exactly where to focus.
The Three Axes of Brownfield Risk
| Axis | Description | Key Questions for Assessment |
|---|---|---|
| Codifiability | How difficult will it be to represent this component as code? This is about technical feasibility. | Does it have an API? Are its configurations declarative or imperative? Is it a well-known service or a bespoke system? |
| Business Impact | What is the cost to the business if this component fails or is misconfigured? This measures criticality. | Is this component in a revenue path? Does it support a critical internal process? What’s the real Mean Time to Recovery (MTTR)? |
| Security Vulnerability | What is the security risk of this component in its current state? This measures your exposure. | Is the OS past end-of-life? Are patches applied inconsistently? Does it handle PII or financial data? Is it exposed to the public internet? |
Components with high scores across all three axes are your biggest liabilities, but they are not your first pilot candidates. Your first IaC pilots should target components with moderate business impact and high codifiability. This lets your team build skills and score early wins, building momentum to tackle the high-risk parts of your estate.
Designing Your Hybrid IaC Architecture
A “big bang” IaC rollout for a legacy environment is not a strategy. It’s a career-limiting move. The only path that works is a pragmatic hybrid architecture that accepts the messy reality of your current state. New, code-defined infrastructure must coexist with manually configured, undocumented systems. This isn’t a temporary compromise; it’s a multi-year strategic bridge to deliver incremental, high-impact wins.
Embrace the Strangler Fig Pattern for Infrastructure
The Strangler Fig pattern, famous for application monoliths, is even more powerful for infrastructure. You build new, IaC-managed services that intercept and replace legacy functions over time. Instead of cracking open a brittle, undocumented system, you build around it and slowly starve it of responsibility.
This worked perfectly with a client’s ancient, manually configured F5 load balancer. Trying to automate it directly was a nightmare. Instead:
- First, we introduced a new API Gateway, managed entirely by Terraform, and placed it in front of the old load balancer. Initially, it just passed all traffic straight through.
- Next, we identified a single, low-risk API endpoint and rebuilt its backend logic as a new serverless function, also managed by IaC.
- Then, we updated the new gateway’s routing rules. Traffic for that specific endpoint now went to our new function. Everything else continued to the legacy stack.
- We repeated this, endpoint by endpoint. Over six months, the old F5 was doing nothing. Decommissioning it was a non-event.
This is how you win. Each strangled service becomes more reliable, scalable, and secure, delivering immediate value without the high-stakes risk of a cutover migration.
Build an Anti-Corruption Layer
Your new IaC-managed services cannot talk directly to the old world. That’s how you import legacy baggage—weird data formats and brittle APIs—into your modern stack. You need a dedicated buffer: an anti-corruption layer (ACL).
An anti-corruption layer is non-negotiable. It’s the Kevlar vest that stops legacy problems from poisoning your modernization budget and timeline.
A classic example is a new microservice needing customer data from a 30-year-old mainframe. Instead of teaching your .NET developer COBOL, you build an ACL that:
- Exposes a clean, modern RESTful API to the new service.
- Handles the ugly connection and session logic to the mainframe behind the scenes.
- Transforms the mainframe’s data into clean JSON.
This completely decouples the two worlds. Your new services can evolve at cloud speed, unaware they are talking to a system from the Reagan administration.
Managing the Seams with IaC Tooling
The success of this hybrid model hinges on your IaC tooling. You need tools that embrace heterogeneity, not just a single cloud provider’s happy path. Tools like Terraform and Pulumi shine here, thanks to their massive provider ecosystems that can talk to everything from on-prem VMware to cloud-native services.
Your IaC code must define the seams that connect the old and new worlds. This includes:
- Network Connections: VPNs, Direct Connect circuits, and firewall rules should live in version control.
- Data Sources: Use features like Terraform’s
datasources to actively query the legacy environment and dynamically configure a new resource. - Policy as Code: Implement a tool like Open Policy Agent (OPA) to enforce consistent security and governance rules across both environments.
When you codify these connection points, the chaotic boundary between old and new becomes a well-defined, version-controlled, and auditable interface.
Choosing the Right Tools and Implementation Partners
Picking an IaC tool for a legacy environment isn’t a simple Terraform vs Ansible beauty contest. Your main concern isn’t elegant syntax; it’s whether a tool’s providers can talk to your ancient, proprietary hardware.
The partner you choose is even more critical. A generic DevOps consultancy that has only ever seen greenfield AWS projects will fail. They will apply cloud-native patterns that don’t fit and burn through your budget. The right partner has battle scars from migrating systems like yours. This decision is where a successful adoption separates from a stalled, multi-million dollar write-off.
A Decision Framework for Tool Selection
In a brownfield project, your evaluation must start with the ecosystem’s ability to interface with your non-cloud-native world.
- Provider Coverage: This is your first filter. Does the tool have mature providers for your exact on-prem gear (specific versions of vSphere, Cisco ACI, F5 BIG-IP, NetApp)? If you have to write custom providers for core infrastructure, you’re already behind.
- State Management Reality: How will you manage the state file? Self-hosting state is an operational burden. Using a service like Terraform Cloud might trip compliance or security alarms if your legacy environment handles regulated data.
- Imperative Escape Hatches: The goal is declarative, but reality is messy. You will need to run imperative, one-off commands against older systems. A tool like Ansible is a powerful sidekick here, handling the procedural tasks that declarative tools like Terraform choke on.
- Community vs. Enterprise Support: For obscure legacy hardware, a niche open-source community might be your only hope. For business-critical systems, a paid enterprise support contract is non-negotiable.
Vetting Implementation Partners Who Get Legacy
The financial stakes are enormous. We’ve seen manual operations in legacy environments cost $1.50 to $4.00 per line in rework. IaC promises to slash that, with some vendors reporting ROI over 300% in 18 months. However, 40% of legacy-to-IaC failures stem from unaddressed technical debt, mirroring internal research where unguided migrations show a 67% failure rate. For more on market dynamics, you can read the full research on the infrastructure as code market.
Choosing a partner is not about finding the best Terraform experts. It’s about finding experts in migrating your specific kind of legacy stack, who also happen to be experts in Terraform.
Use this checklist to cut through sales pitches:
- Demand Documented Case Studies: Ask for proof they’ve worked with stacks similar to yours—mainframe connectivity, AS/400 integrations, or your specific on-prem hypervisor.
- Evaluate Their Discovery Process: How do they plan to map your undocumented environment? A real expert will talk about interviewing senior engineers, analyzing config files, and tracing network paths.
- Scrutinize Their Knowledge Transfer Plan: A good partner’s primary goal is to make themselves redundant. How will they upskill your team and hand over the keys?
- Ask About a Past Failure: Ask them to describe a legacy IaC project that went wrong and what they learned. Their answer will reveal more about their problem-solving skills than any success story.
Pairing the right tool with an experienced partner is the most effective way to de-risk your IaC adoption. For more guidance on integrating these new workflows, see our guide on DevOps integration for modernization.
Executing a Phased Rollout from Pilot to Production
Execution is the hard part. The single biggest mistake is attempting a “big bang” cutover. A successful rollout is a deliberate, phased campaign. You start small, prove undeniable value, and use each win to fund the next stage. It all hinges on showing tangible ROI. A successful pilot doesn’t just “work”—it spits out hard data on deployment speed, stability, and cost savings that becomes the political capital you need to keep going.
Selecting a High-Impact, Low-Risk Pilot
Think of your first pilot as a political tool. It needs to be complex enough to prove the model but not so critical that a failure causes a major business outage.
Look for a workload that hits this sweet spot:
- Non-Critical but Representative: Don’t pick your core billing system. Choose an internal-facing application or a secondary business function that mirrors the architecture of more critical systems without being on the primary revenue path.
- High Manual Toil: Find a system that’s a nightmare to manage. Is there an app that requires a 20-page document for every deployment? Perfect. This gives you a clear “before-and-after” story.
- A Willing Team: The team managing the pilot system must be on board. A resistant team will kill the project. Find engineers who are fed up with the old way of doing things.
Before you even touch the pilot, your tool and partner selection process must be locked in.
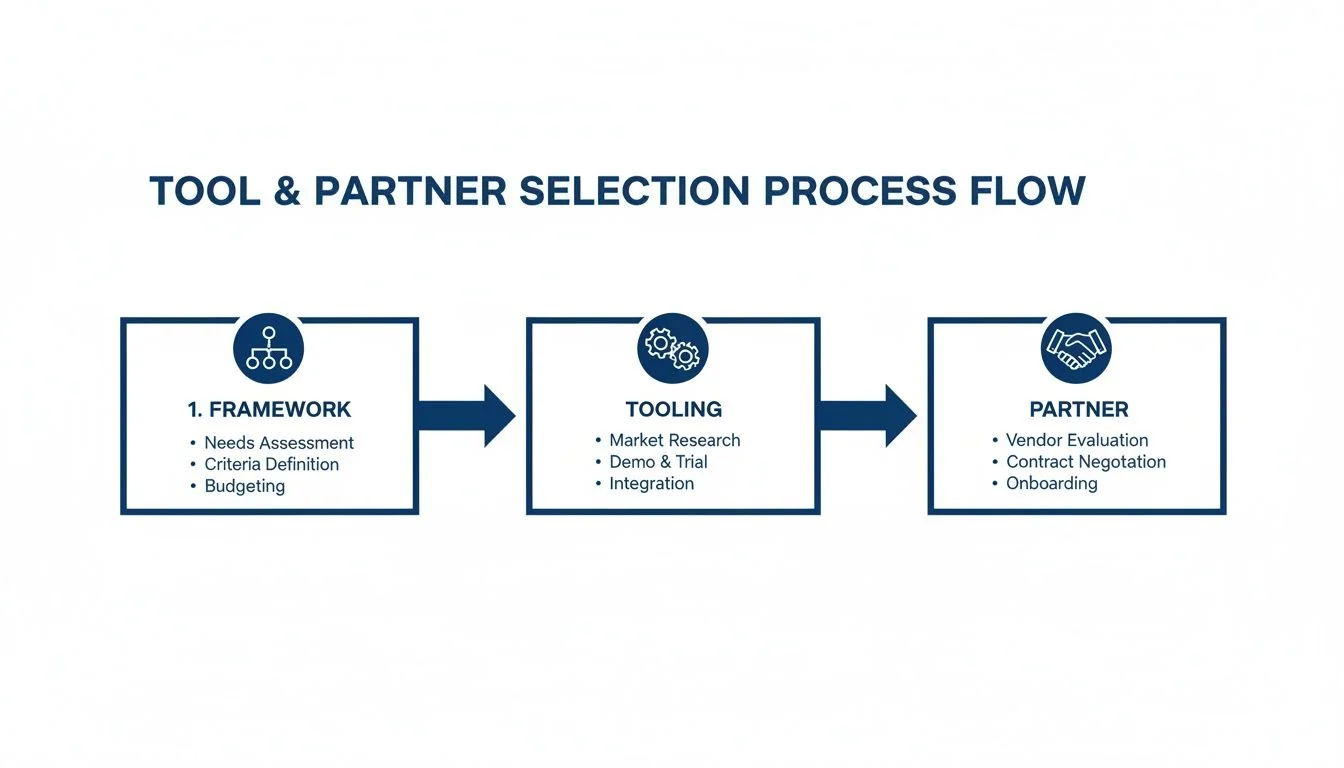
This process ensures your tooling choices are aligned with your goals from day one, preventing costly pivots mid-pilot.
Defining and Measuring Pilot Success
“We did it!” is not a success metric. You need to quantify operational gains. Establish a baseline for these numbers before you start, and measure them again when you’re done.
- Lead Time for Changes: How long does it take to get a simple change from request to production? If it’s weeks, your pilot needs to get it down to hours.
- Deployment Frequency: IaC should enable a shift toward on-demand deployments.
- Mean Time to Recovery (MTTR): When something breaks, how long does it take to fix? The ability to redeploy a known-good state from code should slash MTTR from hours to minutes.
- Change Failure Rate: What percentage of your deployments cause an incident? A solid IaC pilot will drive this number down dramatically.
A successful pilot is not a technical demo. It is a business case proven with operational data. Your goal is to show a 20-30% reduction in manual effort and a 50% or greater improvement in MTTR for the pilot workload.
Scaling with a Cell-Based Rollout
After your pilot succeeds, resist the temptation to codify the entire data center. This is the second most common failure point. Instead, you scale your success using a “cell-based” approach. Your pilot becomes the blueprint. The IaC modules and pipelines you just built are your first reusable assets. Now, identify the next “cell”—a slightly more complex application or related group of services—and apply the same patterns.
This creates a powerful flywheel effect:
- Codify the next application “cell” by reusing your existing modules.
- Develop new, standardized modules only for the unique components in that cell.
- Add those new modules to your central library.
- The next migration gets even faster.
With each new cell under IaC management, your library of tested, reusable code grows, and the time to onboard the next system shrinks. You are methodically replacing fragile, manual processes with auditable, repeatable code.
Next Steps: Answering the Hard Questions on Legacy IaC Adoption
When you’re staring down a decade of undocumented infrastructure, the typical Infrastructure as Code (IaC) sales pitch feels hollow. As a leader, you’re not asking about the “what” but the “how”—the messy, pragmatic questions about making this work in the real world. Here are the direct answers we give CTOs and VPs of Engineering, based on what we’ve seen succeed and fail.
How do we handle undocumented ‘pet’ servers?
Accept reality: you cannot turn every hand-reared ‘pet’ server into disposable ‘cattle’ overnight. The initial goal isn’t ideological purity; it’s risk reduction. Forget asking people what a server does—they’ll tell you what they remember, not what’s true today. Start by using discovery tools to map its actual network traffic. This gives you a ground truth of its real dependencies. From there, it’s a game of “contain and replace.”
- Contain: Don’t touch the pet. Instead, put a cage around it. Isolate the server behind a new, IaC-managed API gateway or load balancer. This instantly gives you a codified, controllable entry point.
- Replace: Apply the Strangler Fig pattern, but be surgical. Pinpoint one specific function the server handles, rebuild just that piece as a modern service (like a serverless function), and then flip the traffic for that single function at your new gateway.
Repeat this, function by function. You’re systematically dismantling the old server’s responsibilities without a high-stakes, big-bang cutover.
What’s the real reason most legacy IaC projects fail?
The number one failure point isn’t the tech; it’s a lack of strategy that defaults to a “tool-first” approach. A team gets excited about Terraform or Pulumi and dives headfirst into codifying a small part of the mess without first understanding the scale of the chaos or defining a win. This leads to fragmented efforts and zero demonstrable ROI.
The root cause of failure is strategic, not technical. It’s the failure to treat IaC adoption as a fundamental operational shift, not just another technology project.
The prevention is simple, if not easy: Do not write a single line of IaC until you have a baseline map of your brownfield environment and have defined what a successful pilot looks like. This means clear, measurable goals, like slashing your Mean Time to Recovery (MTTR) or reducing manual deployment hours.
Should we mandate a single IaC tool or allow a mix?
Go with a mix. The “one tool to rule them all” approach is a fantasy in any real-world brownfield environment. Your legacy estate is a chaotic museum of different vendors, APIs, and operating systems. A pragmatic approach is to standardize on a primary declarative tool—Terraform is the obvious choice—for provisioning core cloud and modern on-prem resources.
Then, you complement it with an imperative tool like Ansible to handle the dirty work: configuration management on older systems, running one-off tasks on machines that lack proper APIs, and patching things that were never designed for automation. This combination gives you declarative elegance where you can and procedural power where you must.
How do we actually measure the ROI of this?
To justify the high upfront investment, you have to move beyond simple infrastructure cost savings. The real ROI is in operational efficiency, risk reduction, and speed. Track these metrics before your pilot begins, and then show the delta after.
- Engineer Toil Reduction: Get an honest measure of the hours your team spends on manual deployments and patching. A successful pilot should cut this waste by at least 20-30%.
- Mean Time to Recovery (MTTR): This is your killer metric. Your ability to redeploy a known-good state entirely from code should slash MTTR by over 50%.
- Change Failure Rate: Track the percentage of deployments that trigger a production incident. Show, with data, how IaC-driven validation and automated rollbacks directly reduce this number.
The ROI isn’t “we saved a little money on servers.” It’s “we reclaimed 500 engineering hours this quarter and can now recover from a critical outage in minutes instead of hours.” That’s a language the C-suite will fund.