
A Pragmatist's Guide to ETL Pipeline Modernization
Your legacy ETL pipelines are a direct liability. They fail silently, corrupt data, and prevent your organization from using its most valuable asset. The choice is no longer whether to modernize, but how to execute the project without derailing the business. ETL pipeline modernization means replacing these brittle, on-premise batch jobs with cloud-native architectures that support the speed and scale of modern analytics. This is a salvage operation for your data strategy.
The Business Case: Why Legacy ETL Fails
Brittle, script-based ETL processes are a primary cause of failed data initiatives. These systems, designed for predictable on-premise data warehouses, cannot handle the volume, velocity, and variety of data from SaaS APIs, event streams, and unstructured sources. This architectural mismatch creates a cascade of operational failures that directly impacts business outcomes. A staggering 70% of data initiatives fail to achieve their goals, frequently due to poor data quality and pipeline fragility rooted in legacy ETL.
Anatomy of an ETL Failure
When legacy pipelines break, the consequences are immediate and severe:
- SLA Breaches: Fragile, sequential batch jobs fail or exceed their processing windows. Critical BI reports are delayed, leaving executives to make decisions based on stale or incomplete information.
- Data Corruption via Schema Drift: A source SaaS application updates its API. The legacy pipeline, lacking automated schema detection, either breaks or, worse, silently ingests corrupted data. This erodes trust in all analytics and renders dashboards dangerously inaccurate.
- Scale Limitations: On-premise ETL servers choke on modern data volumes. This forces a costly and unsustainable cycle of procuring and provisioning hardware that is obsolete upon arrival.
A fundamental limitation of legacy ETL is its inability to process diverse data types. The challenge of structuring unstructured data from logs, documents, or event streams is a key driver for modernization that old tools cannot address.
Inaction is not a viable strategy. Each failed batch job, corrupted dataset, and missed analytical opportunity represents a direct cost of maintaining outdated systems. These pipelines treat data processing as a rigid, sequential task in a world that demands fluid, continuous insight.
These technical failures are symptoms of a larger architectural problem. As detailed in our guide on legacy system modernization, delaying this transition accumulates technical debt and surrenders competitive advantage.
Decision Point: ETL vs. ELT vs. Streaming Architecture
Choosing the target architecture—ETL, ELT, or real-time streaming—is the most critical decision in a modernization project. This choice dictates the cost structure, performance ceiling, and operational model for the next 5-10 years.
- Modern ETL (Replatformed): Retains the Extract, Transform, Load sequence but runs on managed cloud services. Data is transformed in a dedicated processing engine before being loaded into the data warehouse.
- Modern ELT (Re-architected): Flips the pattern to Extract, Load, Transform. Raw data is loaded directly into a cloud data warehouse, where it is transformed using the warehouse’s own powerful compute engine.
- Real-time Streaming: Abandons batches entirely. Data is processed event-by-event as it is generated, enabling immediate action based on live information.
This is not a technical preference; it is a direct response to a specific business requirement, whether for periodic reporting or instant fraud detection.
The Modernized ETL Pattern
Retaining an ETL pattern is a valid choice when executed on cloud-native services like AWS Glue or Azure Data Factory.
This approach is necessary in specific scenarios:
- Data requires heavy cleaning, masking, or anonymization before entering the warehouse. This is a non-negotiable requirement in regulated industries where raw PII cannot be stored, even temporarily, in the target system.
- Transformations are complex, multi-stage, and poorly suited for SQL. These often benefit from the procedural control of languages like Python or Scala in a dedicated processing environment.
- The risk of a full ELT rewrite is unacceptable. A replatforming of existing logic can be a lower-risk first step, preserving institutional knowledge while shedding operational overhead.
The Default: Modern ELT
ELT (Extract, Load, Transform) is the default architecture for modern analytics. Raw data is loaded directly into a cloud data warehouse (Snowflake, BigQuery, Databricks), and transformations are executed post-load using SQL-based tools like dbt.
ELT’s efficiency stems from the separation of storage and compute in the cloud. Loading raw data is inexpensive. You pay for compute resources only during active transformation, eliminating the high fixed cost of an always-on ETL server.
This model is the correct choice when:
- Flexibility is paramount. Analysts and data scientists require direct access to raw data to build custom models and answer novel business questions.
- Source systems are diverse and change frequently. Separating ingestion from transformation means a schema change in one source does not break the entire pipeline—only the specific downstream models that depend on that field.
- Ingestion speed is a priority. Data is landed as it arrives, without waiting for upstream transformations to complete.
While ETL tools still hold a 39.46% revenue share, the fastest-growing segment is real-time and ELT pipelines. The shift to remote work during the COVID-19 pandemic accelerated this trend, as the explosion in unstructured data forced companies to adopt more agile data architectures. More details on these market dynamics are available in Grandview Research’s report on data pipeline tools.
The only viable path forward is to commit to a modernization strategy.
The Specialist: Real-Time Streaming
Streaming architecture processes data event-by-event in near real-time, using technologies like Apache Kafka, Amazon Kinesis, or Google Pub/Sub.
Choose streaming only when the business case requires immediate action. Use cases include:
- Real-time fraud detection in financial transactions.
- Dynamic pricing in e-commerce based on live user behavior.
- Predictive maintenance alerts from industrial IoT sensors.
- Instantaneous user experience personalization.
Streaming is the most operationally complex architecture. It demands specialized engineering skills to manage state, handle out-of-order events, and ensure processing guarantees. It is a powerful tool for specific, latency-sensitive use cases, not a general replacement for batch processing.
Data Architecture Decision Matrix
| Attribute | Modern ETL (Replatform) | Modern ELT (Re-architect) | Real-Time Streaming |
|---|---|---|---|
| Primary Use Case | Scheduled batch reporting, regulated data processing | Flexible analytics, data science, ad-hoc queries | Immediate action, operational intelligence |
| Data Latency | Hours to Days | Minutes to Hours | Milliseconds to Seconds |
| Transformation Logic | Pre-load, in a separate engine (Python/Scala) | Post-load, in the warehouse (SQL/dbt) | In-flight, as data flows (Flink/Kafka Streams) |
| Flexibility | Low: Schema-on-write, transformations are fixed | High: Schema-on-read, raw data available | Medium: Defined schema, complex stateful logic |
| Cost Model | High fixed cost (managed ETL service) | Pay-per-query (compute) + low-cost storage | Pay-per-event/message + processing time |
| Skillset Required | Traditional ETL developers | Analytics engineers, SQL experts | Data/streaming engineers (Kafka, Flink) |
| Failure Mode | Entire batch fails if one transformation breaks | Load succeeds; only downstream models fail | Individual message failures, state management bugs |
ELT offers maximum flexibility for analytics, ETL provides control for sensitive data, and streaming delivers speed for real-time operations. A mature data platform uses a hybrid approach, applying the correct pattern to the specific problem.
The 4 Modernization Patterns: Rehost, Replatform, Refactor, Replace
With a target architecture selected, the next step is choosing the migration path. The four “R”s of modernization provide a framework for this, each with a distinct cost, risk profile, and timeline.
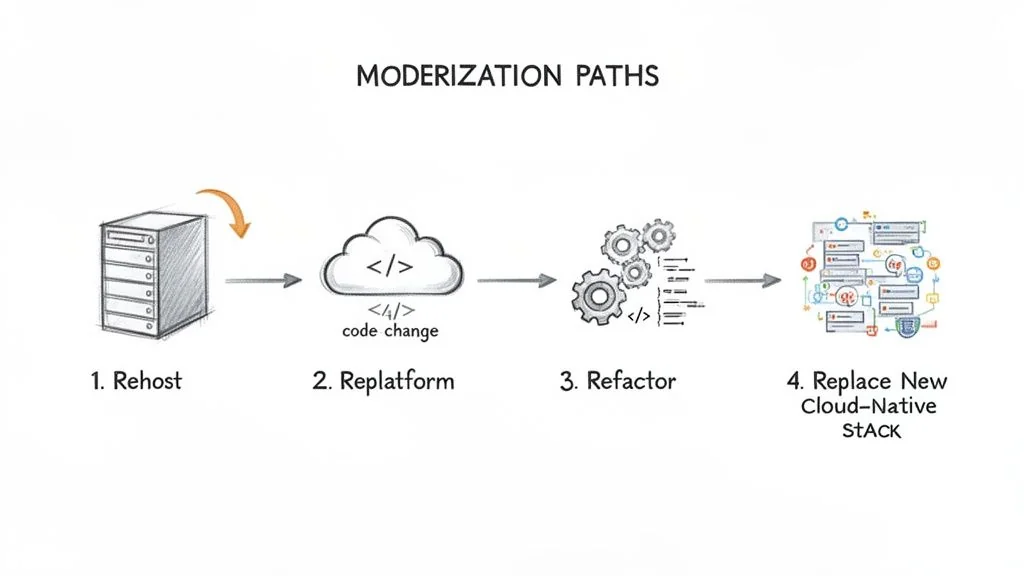
Applying the wrong pattern is a common and costly error. Re-architecting a simple pipeline is waste. Rehosting a critical, broken one merely postpones a future failure.
Path 1: Rehost (Lift-and-Shift)
Rehosting moves existing on-premise ETL servers and software to cloud IaaS. The pipelines themselves remain unchanged. This is not a modernization strategy; it is a data center exit. All underlying problems—brittle jobs, high maintenance, poor scalability—are carried into the cloud. Use this only as a stop-gap measure when facing an imminent data center contract expiration.
Path 2: Replatform
Replatforming migrates existing ETL logic to a managed cloud service like AWS Glue or Azure Data Factory. This involves code modifications but avoids a complete rewrite. The primary benefit is operational: you offload server management, patching, and scaling to the cloud provider.
Replatforming is the optimal path for valuable pipelines with low-to-medium complexity. It delivers a quick win by reducing operational overhead and infrastructure costs without the risk of a full re-architecture.
Path 3: Refactor
Refactoring involves restructuring and optimizing existing pipeline code for better performance, maintainability, and efficiency in the cloud. You improve the code’s internal structure without changing its external behavior. This is a surgical intervention, such as breaking a monolithic script into modular tasks orchestrated by Apache Airflow or rewriting a bottlenecked transformation to leverage a cloud data warehouse’s parallel processing engine.
Refactor when:
- The pipeline’s core business logic is sound, but its implementation is poor.
- You must improve performance or reliability but cannot justify a full replacement.
- You want to introduce DataOps practices like CI/CD and automated testing to a critical pipeline.
Refactoring requires more engineering effort than replatforming but yields significant improvements in performance and agility. It is how you begin to pay down the technical debt that makes legacy systems so fragile.
Path 4: Replace (Re-architect)
Replacement decommissions the legacy pipeline and builds a cloud-native solution from the ground up. This is a fundamental architectural shift, typically from on-premise batch ETL to a cloud-native ELT or streaming pattern. This path is reserved for the most critical, complex, or broken pipelines where incremental fixes are insufficient. A re-architecture is justified when it unlocks entirely new business capabilities, such as replacing a nightly batch job with a real-time fraud detection engine.
Replacement offers the highest ROI but also carries the most risk, cost, and complexity. It demands a strong business case, robust architectural governance, and a phased execution plan with rigorous data validation.
A 5-Step Execution Framework
A structured, defensible plan is essential for turning a modernization strategy into a successful program. This five-step framework provides a practical roadmap for technical leaders to execute a migration, set clear milestones, and demonstrate business value.
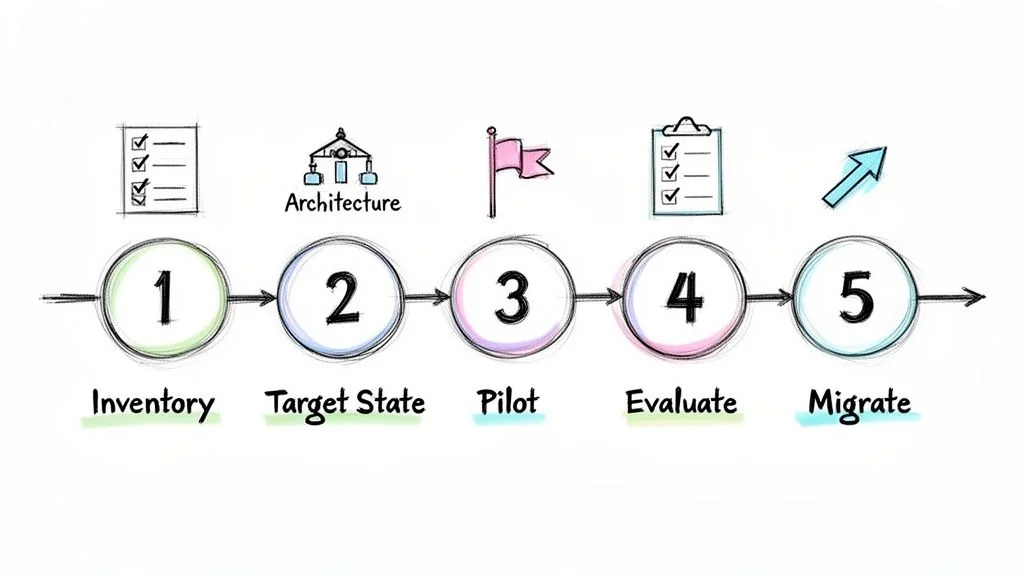
Step 1: Inventory and Triage Your Pipelines
The first step is a comprehensive inventory of all production ETL pipelines. Use automated tools to map data lineage and dependencies, as these are almost always poorly documented. Triage each pipeline using a simple matrix:
- Business Criticality: Tier 0 (mission-critical, business stops on failure), Tier 1 (business-impacting), or Tier 2 (non-critical).
- Technical Fragility: How often does this pipeline break or require manual intervention? (High, Medium, Low).
This exercise identifies your highest-priority targets: a Tier 0, high-fragility pipeline is a ticking time bomb and a prime candidate for the first migration wave.
Step 2: Define the Target State Architecture
Based on the inventory, commit to a target architecture—modern ETL, cloud-native ELT, or real-time streaming. This decision must be driven by business needs. If the goal is analyst empowerment, an ELT architecture is the clear choice. If the requirement is immediate action on operational data, a streaming architecture is necessary.
The target state is a set of principles and standardized patterns, not just a diagram. Standardize on specific tools for ingestion, orchestration (e.g., Apache Airflow), and data quality to prevent the new system from becoming the next generation of technical debt.
Step 3: Select a High-Impact Pilot Project
Do not attempt a “big bang” migration. Select a single, well-defined pilot project to build momentum and secure stakeholder buy-in. The ideal pilot pipeline is:
- High-Impact: Its business users will experience a tangible improvement, turning them into internal champions.
- Low-Risk: It is not a Tier 0 pipeline where a migration error would be catastrophic.
- Representative: Its patterns and complexity are typical of other pipelines, allowing your team to create a reusable migration playbook.
A successful pilot validates the architecture and provides the team with hands-on experience, turning a theoretical plan into a concrete success.
Step 4: Evaluate Tools and Partners
With a target architecture and pilot project defined, evaluate technology and potential implementation partners based on a scorecard mapped to your project’s specific needs, not marketing hype.
Key evaluation criteria include:
- Integration Capabilities: Does the tool connect natively to your specific sources and targets?
- Ecosystem: Is there a strong open-source community or partner network?
- Data Gravity: Choose tools native to your primary cloud provider (AWS, GCP, Azure) to minimize data transfer costs and latency.
- Partner Specialization: Seek partners with proven, niche experience in your specific migration path (e.g., legacy Informatica to cloud ELT), not generalist cloud consultants.
This focused evaluation ensures you select tools and partners that solve your actual problems.
Step 5: Execute a Phased and Validated Migration
The migration must be a phased and meticulously validated process. Run the new, modernized pipeline in parallel with the legacy system for a set period. This parallel run is non-negotiable for performing rigorous data validation. Compare outputs from both systems, checking row counts, checksums, and business-level KPIs to ensure 100% data integrity.
Only after the new pipeline is proven to be reliable and accurate should you begin methodically decommissioning the old system. This phased approach minimizes risk and ensures a seamless transition with zero business disruption.
Costs, Risks, and How to Avoid Failure
Modernizing ETL is a major investment where hidden costs and predictable failures can derail the project. The sticker price of a new tool is trivial compared to the cost of migration labor, cloud consumption, and parallel run environments.
The true cost of ETL pipeline modernization is in the specialized labor required for migration and the long-term operational expense of the new platform.
Real-World Cost Drivers
Budgeting for modernization requires looking beyond software licenses. The largest line items are specialized services and cloud compute. Code migration services, for example, are often priced per line of code, with rates between $1.50 and $4.00 per LOC to convert legacy logic to a modern platform.
Other significant cost drivers include:
- Cloud Infrastructure Spend: In an ELT model, poorly optimized queries can generate thousands of dollars in unexpected compute costs. Strict governance is required to prevent this.
- Parallel Run Expenses: Running old and new pipelines simultaneously is expensive, as it doubles your production environment costs for a period of weeks or months. This is a necessary insurance policy against data integrity failures.
- Data Validation and Reconciliation: This requires significant, dedicated engineering time to build automated tests and prove the new pipeline produces identical results to the old one.
Our guide on modernization project costs provides more detailed financial models.
Common Failure Modes
Project failures are rarely a surprise. They are the result of predictable pitfalls that were not addressed upfront. A reported 67% of modernization initiatives fail to meet their objectives due to avoidable mistakes. As noted in this market intelligence report, navigating these challenges is a critical executive function.
The most common project-killers are:
- Data Integrity Loss: The new pipeline goes live, but the data is wrong. Trust in the entire data platform is immediately destroyed.
- Mitigation: A mandatory parallel run phase with automated, rigorous data validation is the only way to prevent this. Do not decommission the legacy system until you can prove the new one is 100% accurate.
- Vendor Lock-in: Choosing a proprietary, all-in-one platform makes future changes prohibitively expensive and complex.
- Mitigation: Prioritize tools built on open standards like SQL. Design an architecture with replaceable components, not a monolith.
- Neglecting Data Governance: The new, flexible ELT architecture exposes raw, sensitive data, creating a massive compliance and security risk.
- Mitigation: Build data governance and security into the architecture from day one. This includes policy-as-code for access control, automated data masking, and a clear data ownership model.
Next Steps: Selecting the Right Partner and Technology
Success depends on a brutally honest evaluation of technology and partners that cuts through marketing and focuses on specialized, proven expertise. You can assemble a best-of-breed stack using tools like Fivetran for ingestion and dbt for transformation, or you can opt for an all-in-one platform. The correct choice depends on your team’s skills, target architecture, and tolerance for vendor lock-in. A thorough comparison of the best data pipeline tools is a critical step.
Demand Niche Expertise
A partner’s value is not in their cloud certifications, but in their battle-tested experience with your exact migration scenario. A partner with deep expertise in migrating legacy Informatica to a Snowflake/dbt stack is infinitely more valuable than a generalist cloud consultant. Niche expertise is the only thing that matters.
Your RFP must demand proof. Ask for specific, referenceable case studies that mirror your legacy stack, target architecture, and industry. Vague claims of “ETL modernization experience” are a red flag.
Use your RFP to test for real-world knowledge:
- Scenario Prompt: “Given our legacy pipeline (e.g., Informatica on Oracle), describe your phased approach for migrating it to an ELT pattern using Snowflake and dbt, including your data validation strategy for each phase.”
- Metrics Prompt: “Provide anonymized metrics from a relevant past project showing pre- and post-migration data latency, processing cost-per-TB, and error rates.”
Your Action Plan
- Build the Business Case: Use the inventory and triage framework to quantify the risk of inaction. Secure executive buy-in for a focused pilot project.
- Launch the Pilot: A successful pilot de-risks the technology, validates your architectural choices, and builds organizational momentum.
- Engage a Specialist Partner: Armed with a clear plan and a funded pilot, find a partner who demonstrates a deep, obsessive understanding of your specific modernization challenge. The right partner will accelerate your timeline, mitigate known risks, and ensure your new data platform becomes a strategic asset, not the next generation of technical debt.